第7章 Just-in-Time编译器
LLVM Just-in-Time (JIT)编译器是一个基于函数的动态翻译引擎。为了理解什么是JIT编译器,让我们回顾原始的术语。这个术语来自Just-in-Time制造,一种商业策略,即工厂按需制造或者购买物资,而不引入库存。在编译过程中,这个比喻很合适,因为JIT编译器不会将二进制程序存储到磁盘(库存),而是在你需要它们的时候开始编译程序部分。尽管人们接受了业内行话,你可能还困惑于其它的名字,例如延时(late)或者懒惰(lazy)编译。
JIT策略的优势在于知道将运行程序的精确的机器和微架构。这让JIT系统能够为特定的处理器微调代码。而且,有的编译器只有在运行时知道其输入,因而只能实现为JIT系统,除此之外别无选项。例如,GPU驱动程序即时编译着色语言,互联网浏览器处理JavaScript也是如此。在这一章中,我们将探索LLVM JIT系统,讨论下列内容:
llvm::JIT类和它的基础结构
如何利用llvm::JIT类执行JIT编译
如何利用GenericValue简化函数调用
llvm::MCJIT类和它的基础结构
如何利用llvm::MCJIT类执行JIT编译
了解LLVM JIT引擎基础
LLVM JIT编译器是基于函数的,因为它一次能够编译单个函数。这定义了编译器的工作粒度,对于JIT系统来说是一个重要的决定。通过按需编译函数,编译器只会处理当前程序调用中实际用到的函数。例如,你的程序有若干个函数,你在启动它的时候设置了错误的命令行参数,一个基于函数的JIT系统只会编译那个打印帮助消息的函数,而不是这个程序。
备注
理论上,我们可以进一步细化粒度,只编译执行踪迹(trace),就是函数的具体的线路。如此,我们已经利用了JIT系统的重要优势:对于给定输入的一次程序调用,知道应该尽力去编译哪个程序线路,而不是其它的。然而,LLVM JIT系统并不支持基于踪迹的编译,一般来说,它更受研究者的关注。关于JIT编译的讨论没有尽头,大量不同的权衡值得仔细研究,指出哪种策略最优不是一件简单的事。目前,计算机科学社区积累了大约20年的对JIT编译的研究,这个领域仍然非常活跃,每年都有新的论文尝试解决这个开放的问题。
JIT引擎在运行时编译并且执行LLVM IR函数。在编译阶段,JIT引擎会用LLVM代码生成器生成由目标特定的二进制指令组成的二进制数据块。它返回一个指向所编译函数的指针,这个函数可以被执行。
小技巧
一篇有趣的博客文章对比了JIT编译的开源解决方案,见 https://eli.thegreenplace.net/2014/01/15/some-thoughts-on-llvm-vs-libjit,它分析了LLVM和libjit,后者是一个小型的致力于JIT编译的开源项目。LLVM作为静态编译器比JIT系统更加有名,因为在JIT编译过程中,每个Pass消耗的时间是很重要的,算作程序执行的开销。LLVM基础架构更注重支持慢而强的优化,和GCC相似,而不是快而弱的优化,后者对构建一个有竞争力的JIT系统很重要。尽管如此,LLVM已经被成功地应用于JIT系统来建立Webkit JavaScript引擎的第四级LLVM(Fourth Tier LLVM, FTL)组件(http://blog.llvm.org/2014/07/ftl-webkits-llvm-based-jit.html)。因为第四级只用在长时间运行的JavaScript应用程序,激进的LLVM优化可以发挥作用,即使它们不如更低级的优化快。从理性来看,如果应用程序运行时间长,我们就可以在代价高的优化上付出更多时间。想要了解更多关于这种权衡,参看Modeling Virtual Machines Misprediction Overhead,作者Cesar et al.,发表于IISWC 2013,它分析揭示了JIT系统在多大程度上因为对不值得的代码使用了高代价的代码生成而受损失。当你的JIT系统浪费大量时间去优化一个仅执行若干次的程序片段时,这种情况就发生了。
介绍执行引擎
LLVM JIT系统采用了一个执行引擎来支持LLVM模块的执行。ExecutionEngine类在<llvm_source>/include/llvm/ExecutionEngine/ExecutionEngine.h中定义,它被设计出来以支持执行,通过JIT系统或者解释器(参考后面的信息盒子)。一般来说,一个执行引擎负责管理整个宾客程序的执行,分析接下来需要运行的程序片段,采取合理的动作来执行它。要作JIT编译,必须有一个执行管理器来协调编译决策,运行宾客程序(一次一个片段)。就LLVM的ExecutionEngine类而言,它将执行部分抛回给你,即客户。它可以运行编译管线,产生驻留内存的代码,但是由你决定是否执行此代码。
除了接受LLVM模块并执行它,引擎支持下面几个场景:
懒惰(lazy)编译:函数被调用时,引擎才编译它。关闭懒惰编译后,一旦你请求指向函数的指针,引擎就编译它们。
编译外部全局变量:这包括对当前LLVM模块的外部实体的符号解析和内存分配。
通过dlsym查找和解析外部符号:这个过程和运行时动态共享对象(dynamic shared object, DSO)加载一样。
LLVM实现了两个执行引擎:llvm::JIT类和llvm::MCJIT类。ExecutionEngine::EngineBuilder()方法实例化一个ExecutionEngine对象,根据一个IR模块参数。接着,ExecutionEngine::create()方法创建一个JIT或者MCJIT实例,两者的实现截然不同,这正是这一章要讲清楚的内容。
备注
解释器实现了一种非传统的策略来执行宾客代码,就是硬件平台(宿主平台)不原生地支持此代码。例如,LLVM IR是x86平台上的宾客代码,因为x86处理器不能之间执行LLVM IR。不同于JIT编译器,解释器的任务是读取每条指令,解码它们并执行它们的行为,在软件中模仿物理处理器的功能。尽管解释器省去了启动编译器翻译宾客代码的时间,它们往往慢得多,除非编译宾客代码所需的时间不能抵消解释代码的高额开销。
内存管理
一般来说,JIT引擎在运行时将二进制数据块写入内存,这是由ExecutionManager类完成的。随后,就可以跳转到分配的内存区域来执行这些指令了,也就是调用ExecutionManager返回给你的函数指针。在此上下文中,内存管理是极其重要的,处理很多常规的任务,例如分配内存,释放内存,为加载库提供空间,和内存权限管理。
JIT和MCJIT类都实现了一个定制的内存管理类,从基类RTDyldMemoryManager派生而来。任何ExecutionEngine用户可能也提供定制的RTDyldMemoryManager派生类,来指定不同的JIT组件应该被放置在内存的何处。你可以在<llvm_source>/include/llvm/ExecutionEngine/RTDyldMemoryManager.h文件中找这个接口。
例如,RTDyldMemoryManager类声明了如下方法:
allocateCodeSection()和allocateDataSection():这些方法分配内存以存放给定大小和对齐的可执行代码和数据。内存管理的用户可以通过一个内部的section标识符追踪已分配的section。
getSymbolAddress():这个方法返回当前链接的库中可获得的symbol的地址。注意这不是用于获得JIT编译生成的symbol。调用这个方法时,必须提供一个std::string实例以存放symbol的名字。
finalizeMemory():这个方法应该在对象加载完成时被调用,然后终于可以设置内存权限了。举例来说,不能在调用这个方法之前运行生成的代码。正如这一章要进一步解释的那样,这个方法被导向到MCJIT用户而不是JIT用户。
尽管用户可以提供定制的内存管理实现,JITMemoryManager和SectionMemoryManager分别是JIT和MCJIT的默认子类。
介绍llvm::JIT基础结构
JIT类和它的框架代表原先的引擎,它是通过使用LLVM代码生成器的不同部分而实现的。LLVM 3.5之后,它将被移除。尽管这个引擎大部分是目标无关的,每个目标必须为它的具体的指令实现二进制指令输出。
数据块写到内存
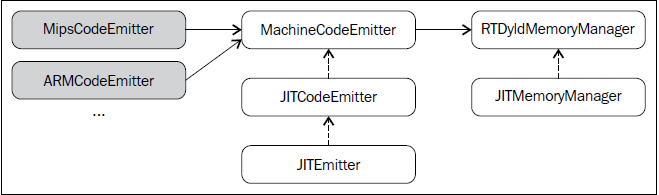
JIT类通过JITCodeEmitter输出二进制指令,它是MachineCodeEmitter类的子类。MachineCodeEmitter类用于机器代码输出,它和新的机器代码(Machine Code, MC)框架是没有联系的——尽管陈旧,它依然存在以支持JIT类的功能。它的局限是只支持若干个目标,对于已经支持的目标,不是所有目标特性都是可用的。
MachineCodeEmitter类的方法使下列任务变得容易:
为当前将输出的函数分配空间
将二进制数据块写到内存缓冲区(emitByte(), emitWordLE(), emitWordBE(), emitAlignment(), 等)
追踪当前缓冲区地址(就是一个指针,指向下一条指令将被在何处输出的地址)
添加重定位,与此缓冲区内的指令地址相关联
将字节写到内存的任务是由JITCodeEmitter执行的,它是参与代码输出过程的另一个类。它是JITCodeEmitter的子类,实现具体的JIT功能和管理。JITCodeEmitter是相当简单的,只是将字节写到缓冲区,而JITEmitter具有下列改进:
专用的内存管理器,JITMemoryManager,之前提到过(也是下一节的主题)。
解决者(JITResolver)实例,跟踪和解决未被编译的函数的调用现场。这对懒惰函数编译是至关重要的。
使用JITMemoryManager
JITMemoryManager类(见<llvm_source>/include/llvm/ExecutionEngine/JITMemoryManager.h)实现了低层级内存处理,为前面提及的类提供缓冲区。除了来自RTDyldMemoryManager的方法,它提供具体的方法来协助JIT类,例如allocateGlobal(),为单个全局变量分配内存;startFunctionBody(),建立JIT调用,分配内存并标记为读/写可执行,以输出指令。
内部地,JITMemoryManager类使用JITSlabAllocator slab分配器(<llvm_source>/lib/ExecutionEngine/JIT/JITMemoryManager.cpp)和MemoryBlock单元(<llvm_source>/include/llvm/Support/Memory.h)。
目标代码输出
每个目标都实现一个机器函数Pass,称为<Target>CodeEmitter(见<llvm_source>/lib/Target/<Target>CodeEmitter.cpp),它将指令编码为数据块,利用JITCodeEmitter写到内存。MipsCodeEmitter,以此为例,遍历所有函数基本块,对于每条机器指令(MI),调用emitInstruction():
(...)
MCE.startFunction(MF);
for (MachineFunction::iterator MBB = MF.begin(), E = MF.end(); MBB != E; ++MBB) {
MCE.StartMachineBasicBlock(MBB);
for (MachineBasicBlock::instr_iterator I = MBB->instr_begin(), E = MBB->instr_end(); I != E;)
emitInstruction(*I++, *MBB);
}
(...)
MIPS32是固定4字节长度的ISA,这使得emitInstruction()的实现很简单。
void MipsCodeEmitter::emitInstruction(MachineBasicBlock::instr_iterator MI, MachineBasicBlock &MBB) {
...
MCE.processDebugLoc(MI->getDebugLoc(), true);
emitWord(getBinaryCodeForInstr(*MI));
++NumEmitted; // Keep tract of the # of mi's emitted
...
}
emitWord()方法是对JITCodeEmitter的包装,getBinaryCodeForInstr()是TableGen为每个目标生成的,通过解读.td文件中的指令编码描述。<Target>CodeEmitter类还必须实现定制的方法以编码操作数和其它目标特定的实体。例如,在MIPS中,内存操作数必须使用getMemEncoding()放以恰当地编码(见<llvm_source>/lib/Target/Mips/MipsInstrInfo.td):
def mem : Operand<iPTR> {
(...)
let MIOperandInfo = (ops ptr_rc, simm16);
let EncoderMethod = "getMemEncoding";
(...)
}
因此,MipsCodeEmitter必须实现MipsCodeEmitter::getMemEncoding()方法以符合这个TableGen描述。下面的示意图显示了几个代码输出器和JIT框架的关系:
目标信息
为了支持Just-in-Time编译,每个目标还必须提供一个TargetJITInfo的子类(见include/llvm/Target/TargetJITInfo.h),例如MipsJITInfo或者X86JITInfo。TargetJITInfo类为通用的JIT功能提供了接口,需要每个目标实现它们。下面,我们来看这些功能的一些例子:
为了支持执行引擎重编译一个函数的需求——或许因为它被修改了——每个目标要实现TargetJITInfo::replaceMachineCodeForFunction()方法,修补原先函数的位置,用指令跳转或调用新版本函数。对于自修改代码,这是必需的。
TargetJITInfo::relocate()方法修补当前输出函数中的每个symbol引用,以指向正确的内存地址,这个做法和动态链接器类似。
TargetJITInfo::emitFunctionStub()方法输出一个代理:一个函数以调用给定地址的另一个函数。每个目标还要为输出的代理提供定制的TargetJITInfo::StubLayout信息,包括字节长度和对齐。JITEmitter会使用这些代理信息为新的代理在输出它之前分配空间。
虽然TargetJITInfo方法的目的不是输出常规的指令,诸如函数体生成,但是它们仍然需要为代理输出具体的指令,调用新的内存位置。然而,当JIT框架建立之后,没有接口可以依赖以使得输出孤立的指令变得容易,它们存在于MachineBasicBlock之外。这是今天MCInsts为MCJIT做的事情。没有MCInsts,原先的JIT框架强制让目标手工编码指令。
为了揭示<Target>JITInfo的实现如何需要手工地输出指令,让我们来看MipsJITInfo::emitFunctionStub()的代码(见<llvm_source>/lib/Target/Mips/MipsJITInfo.cpp),它用以下代码生成4条指令:
...
// lui $t9, %hi(EmittedAddr)
// addiu $t9, $t9, %lo(EmittedAddr)
// jalr $t8, $t9
// nop
if (IsLittleEndian) {
JCE.emitWordLE(0xf << 26 | 25 << 16 | Hi);
JCE.emitWordLE(9 << 26 | 25 << 21 | 25 << 16 | Lo);
JCE.emitWordLE(25 << 21 | 24 << 11 | 9);
JCE.emitWordLE(0);
...
学习如何使用JIT类
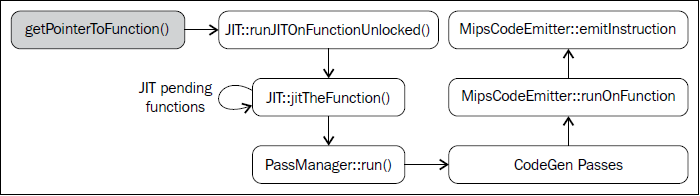
JIT是一个ExecutionEngine子类,声明于<llvm_source>/lib/ExecutionEngine/JIT/JIT.h。JIT类是编译函数的入口,借助JIT基础结构。
ExecutionEngine::create()方法调用JIT::createJIT(),以一个默认的JITMemoryManager。接着,JIT构造器执行下面的任务:
创建JITEmitter实例
初始化目标信息对象
为代码生成添加Pass
添加最后运行的<Target>CodeEmitter Pass
引擎保存了一个PassManager对象,以调用所有的代码生成和JIT输出Pass,每当被请求JIT编译一个函数的时候。
为了阐明一切是怎么发生的,我们已经描述了如何JIT编译sum.bc的一个函数,第5章(LLVM中间表示)和第6章(后端)到处在用此bitcode文件。我们的目的是获取Sum函数,并且用JIT系统计算两个不同的引用运行时参数的加法运算。让我们执行下面的步骤:
首先,创建一个新文件,名为sum-jit.cpp。我们要包含JIT执行引擎的资源:
#include "llvm/ExecutionEngine/JIT.h"
包含其它的头文件,涉及读写LLVM bitcode、上下文接口等,并导入LLVM namespace:
#include "llvm/ADT/OwningPtr.h"
#include "llvm/Bitcode/ReaderWriter.h"
#include "llvm/IR/LLVMContext.h"
#include "llvm/IR/Module.h"
#include "llvm/Support/FileSystem.h"
#include "llvm/Support/MemoryBuffer.h"
#include "llvm/Support/ManagedStatic.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/system_error.h"
#include "llvm/Support/TargetSelect.h"
using namespace llvm;
InitializeNativeTarget()方法设置宿主目标,确保能够链接JIT将用到的目标库。和往常一样,每个线程需要一个上下文LLVMContext对象和一个MemoryBuffer对象,以从磁盘读取bitcode文件,如下面的代码所示:
int main() {
InitializeNativeTarget();
LLVMContext Context;
std::string ErrorMessage;
OwningPtr<MemoryBuffer> Buffer;
用getFile()方法从磁盘读文件,如下面的代码所示:
if (MemoryBuffer::getFile("./sum.bc", Buffer)) {
errs() << "sum.bc not found\n";
return -1;
}
ParseBitcodeFile函数从MemoryBuffer读取数据,生成相应的LLVM Module类以表示它,如下面的代码所示:
Module *M = ParseBitcodeFile(Buffer.get(), Context, &ErrorMessage);
if (!M) {
errs() << ErrorMessage << "\n";
return -1;
}
调用EngineBuilder工厂的create方法创建一个ExecutionEngine实例,如下面的代码所示:
OwningPtr<ExecutionEngine> EE(EngineBuilder(M).create());
这个方法默认创建一个JIT执行引擎,是JIT的设置点;它直接调用JIT构造器来创建JITEmitter、PassManager,并初始化所有代码生成和目标特定的输出(emission)Pass。此刻,尽管引擎接受了一个LLVM Module,还没有编译函数。
为了编译函数,还需要调用getPointerToFunction(),它得到一个指向原生JIT编译的函数的指针。如果这个函数未曾JIT编译过,就作JIT编译并返回函数指针。下图阐明了此编译过程:
通过getFunction()方法获取表示sum函数的函数IR对象:
Function *SumFn = M->getFunction("sum");
这里,JIT编译被触发了:
int (*Sum)(int, int) = (int (*)(int, int)) EE->getPointerToFunction(SumFn);
你需要作一次恰当的类型转换,转换到匹配这个函数的函数指针类型。Sum函数的LLVM定义原型是i32 @sum(i32 %a, i32 %b),因此我们用int (*)(int, int) C原型。
另一个选项是考虑懒惰编译,调用getPointerToFunctionOrStub()而不是getPointerToFunction()。这个方法将生成一个代理函数,并且返回它的指针,如果目标函数还没有被编译并且懒惰编译是开启的。代理是一个简单的函数,包含一个占位符,将来修改占位符就可以跳转/调用实际的函数。
接下来,根据Sum所指向的JIT编译了的函数,调用原始的Sum函数,如下面的代码所示:
int res = Sum(4, 5);
outs() << "Sum result: " << res << "\n";
当使用懒惰编译时,Sum调用代理函数,它会用一个编译回调函数来JIT编译实际的函数。然后修改代理以重定向到实际函数并执行它。除非原始的Module中的Sum函数改变了,这个函数绝不会被再次编译。
再次调用Sum来计算下一个结果,如下面的代码所示:
res = Sum(res, 6);
outs() << "Sum result: " << res << "\n";
在懒惰编译环境中,由于原始的函数在第一次调用Sum时已经编译过了,第二次调用会直接执行原生函数。
我们成功地用JIT编译的Sum函数计算了两次加法。现在,释放执行引擎分配的存放函数代码的内存,调用llvm_shutdown()函数并返回:
EE->freeMachineCodeForFunction(SumFn);
llvm_shutdown();
return 0;
}
要编译并链接sum-jit.cpp,可以用下面的命令行:
$ clang++ sum-jit.cpp -g -O3 -rdynamic -fno-rtti $(llvm-config --cppflags --ldflags --libs jit native irreader) -o sum-jit
或者,利用第3章(工具和设计)的Makefile,添加-rdynamic选项,修改llvm-config调用以使用前面的命令行指定的库。尽管这个例子没有使用外部函数,-rdynamic选项是重要的,它保证外部函数在运行时被解析。
运行这个例子并查看输出:
$ ./sum-jit
Sum result: 9
Sum result: 15
通用值
在前面的例子中,我们将返回的函数指针转换为恰当的原型,为了用C样式的函数调用去调用这个函数。然而,当我们处理多个函数并且它们采用众多的签名和参数类型时,需要一种更灵活的方法去执行它们。
执行引擎提供了另一种调用JIT编译的函数的方法。runFunction()方法编译并运行一个函数,函数参数由GenericValue向量决定——不需要提前调用getPointerToFunction()。
GenericValue struct在<llvm_source>/include/llvm/ExecutionEngine/GenericValue.h中被定义,它能够存放任何通用的类型。让我们修改前面的例子,以使用runFunction()而不是getPointerToFunction()和类型转换。
首先,创建文件sum-jit-gv.cpp以保存这个新的版本,在开头添加GenericValue头文件:
#include "llvm/ExecutionEngine/GenericValue.h"
从sum-jit.cpp复制其余的内容,让我们关注修改部分。在SumFn函数指针初始化之后,创建FnArgs——GenericValue向量——并用APInt接口(<llvm_source>/include/llvm/ADT/APInt.h)填充整数值。根据函数原型sum(i32 %a, i32 %b),填充两个32位长度的整数:
(...)
Function *SumFn = m->getFunction("sum");
std::vector<GenericValue> FnArgs(2);
FnArgs[0].IntVal = APInt(32, 4);
FnArgs[1].IntVal = APInt(32, 5);
以函数变量和参数向量调用runFunction()。这样,函数会被JIT编译并执行。相应地,结果也是GenericValue,可以被访问。
GenericValue Res = EE->runFunction(SumFn, FnArgs);
outs() << "Sum result: " << Res.IntVal << "\n";
重复相同的过程,以执行第二个加法:
FnArgs[0].IntVal = Res.IntVal;
FnArgs[1].IntVal = APInt(32, 6);
Res = EE->runFunction(SumFn, FnArgs);
outs() << "Sum result: " << Res.IntVal << "\n";
(...)
介绍llvm::MCJIT框架
MCJIT类是LLVM新的JIT实现。它和原先的JIT实现的不同在于MC框架,第6章(后端)对此作过探索。MC提供了统一的指令表达方式,它作为一个框架,为汇编器、反汇编器、汇编打印器和MCJIT所共享。
应用MC库的第一个优势在于,目标只需要指定一次它们的指令的编码,因为所有子系统都会得到此信息。因此,当你编写LLVM后端的时候,如果你实现了目标的目标代码输出功能,也就实现了JIT功能。
llvm::JIT将在LLVM 3.5之后被去除,完全替换为llvm::MCJIT框架。那么,我们为何学习原先的JIT呢?虽然它们是不同的实现,但是ExecutionEngine类是通用的,大部分概念是两者共有的。最重要的是,像在LLVM 3.4版本中,MCJIT的设计不支持某些特性,例如懒惰编译,它还不是原先JIT的完全接替者。
MCJIT引擎
创建MCJIT引擎的方法和原先的JIT引擎相同,通过调用ExecutionEngine::create()。这个方法调用MCJIT::createJIT(),它会执行MCJIT构造器。MCJIT类在文件<llvm_source>/lib/ExecutionEngine/MCJIT/MCJIT.h中声明。createJIT()方法和MCJIT构造器在文件<llvm_source>/lib/ExecutionEngine/MCJIT/MCJIT.cpp中实现。
MCJIT构造器创建一个SectionMemoryManager实例;将LLVM模块添加到它内部的模块容器,OwningModuleContainer;并且初始化目标信息。
了解模块的状态
MCJIT类为引擎建立期间插入的初始LLVM模块实例指定状态。这些状态描绘了模块的编译阶段。状态如下:
Added: 这些模块所包含的模块集还没有被编译但已经被添加到执行引擎了。这个状态的存在让模块能够为其它模块暴露函数定义,延迟对它们的编译直到必需之时。
Loaded: 这些模块处在已JIT编译状态但是还未准备好执行。重定位还没有做,内存页面还需要给予恰当的权限。愿意在内存中重映射已JIT编译的函数的用户,也许能避免重编译,通过使用loaded状态的模块。
Finalized: 这些模块包含已经准备好执行的函数。在此状态下,函数不能被重映射了,因为重定位已经做过了。
JIT和MCJIT的一个主要区别就在于模块状态。在MCJIT中,引擎模块必须在请求symbol地址(函数和全局变量)之前就绪(finalized)。
MCJIT::finalizeObject()函数将已添加模块转换为已加载模块,接着转换为已就绪模块。首先,它通过调用generateCodeForModule()生成已加载模块。接着,通过finalizeLoadedModules()方法,所有模块变为就绪模块。
不像原先的JIT,MCJIT::getPointerToFunction()函数要求模块对象在调用之前就绪。因此,必须在使用之前调用MCJIT::finalizeObject()。
LLVM 3.4添加的新方法消除了这种限制——当使用MCJIT时,getPointerToFunction()方法被getFunctionAddress()淘汰了。这个新方法在请求symbol地址之前加载和就绪模块,而不需要调用finalizeObject()。
备注
注意,在原先的JIT中,执行引擎单独地JIT编译和执行各个函数。在MCJIT中,整个模块(所有函数)必须在任何函数执行之前被JIT编译。由于编译粒度变大了,我们不能再说它是基于函数的,而是基于模块的翻译引擎。
理解MCJIT如何编译模块
代码生成发生在模块对象加载阶段,由MCJIT::generateCodeForModule()方法触发,它在<llvm_source>/lib/ExecutionEngine/MCJIT/MCJIT.cpp文件中。这个方法执行下面的任务:
创建一个ObjectBuffer实例以存放模块对象。如果模块对象已经被加载(编译),就用ObjectCache接口获取,避免重编译。
假设没有之前的缓存(cache),MCJIT::emitObject()就执行MC代码生成。结果是一个ObjectBufferStream对象(ObjectBuffer子类,支持streaming)。
RuntimeDyld动态链接器加载结果ObjectBuffer对象,并通过RuntimeDyld::loadObject()建立符号表(symbol table)。这个方法返回一个ObjectImage对象。
模块被标记为已加载。
对象缓冲区,缓存,图像
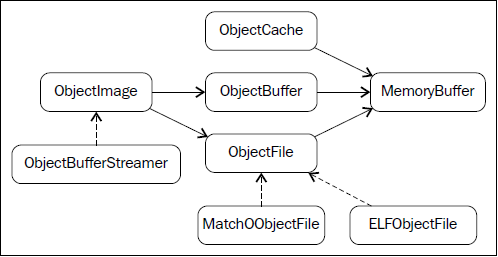
ObjectBuffer类(<llvm_source>/include/llvm/ExecutionEngine/ObjectBuffer.h)实现了对MemoryBuffer类(<llvm_source>/include/llvm/Support/MemoryBuffer.h)的包装。
MCObjectStreamer子类利用MemoryBuffer类输出指令和数据到内存。此外,ObjectCache类直接引用MemoryBuffer实例,能从彼处获取ObjectBuffer。
ObjectBufferStream类是一个ObjectBuffer子类,带有附加的标准C++流运算符(例如,>>和<<),从实现的视角来看,它让内存缓冲区的读写变得容易。
ObjectImage对象(<llvm_source>/include/llvm/ExecutionEngine/ObjectImage.h)用于保持加载的模块,它可以直接访问ObjectBuffer和ObjectFile的引用。ObjectFile对象由目标特定的目标文件类型具体化,例如ELF、COFF、和MachO。ObjectFile对象能够从MemoryBuffer对象直接获取符号、重定位、和段。
下图说明了这些类是怎么相互关联的——实箭头表示协助,虚箭头表示继承。
动态链接
MCJIT加载的模块对象被表示为ObjectImage实例。如前面提到的那样,它可以透明地访问内存缓冲区,通过一个目标无关的ObjectFile接口。因此,它可以处理符号、段、和重定位。
为了生成ObjectImage对象,MCJIT具有动态链接特性,由RuntimeDyld类提供。这个类提供了访问这些特性的公共接口,而RuntimeDyldImpl对象提供实际的实现,它由每个对象的文件类型具体化。
因此,RuntimeDyld::loadObject()方法首先创建目标特定的RuntimeDyldImpl对象,然后调用RuntimeDyldImpl::loadObject()。它根据ObjectBuffer生成ObjectImage对象。在这个过程中,还创建了ObjectFile对象,可以通过ObjectImage对象获取它。下图说明了这个过程:
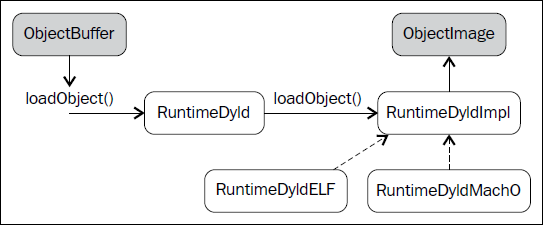
运行时RuntimeDyld动态链接器用于让模块就绪过程中解决重定位,为模块对象注册异常处理帧。回想起执行引擎方法getFunctionAddress()和getPointerToFunction()要求引擎知道符号(函数)地址。为了解决这个问题,MCJIT还用RuntimeDyld获取任意的符号地址,通过RuntimeDyld::getSymbolLoadAddress()方法。
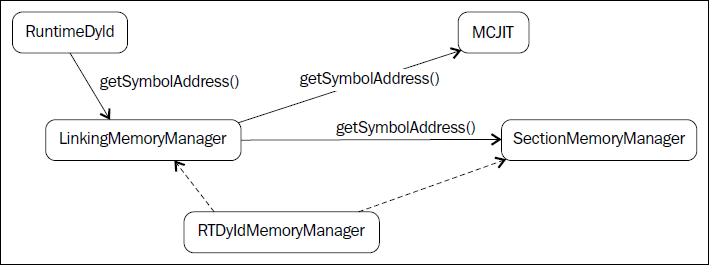
内存管理器
LinkingMemoryManager类,另一个RTDyldMemoryManager子类,是MCJIT引擎所用的实际内存管理器。它聚合了一个SectionMemoryManager实例,向它发送委托请求。
每当RuntimeDyld动态链接器通过LinkingMemoryManager::getSymbolAddress()请求符号地址时,它有两个选择:如果符号在一个已编译的模块中是可获得的,就从MCJIT获取地址;否则,从外部库请求地址,它们由SectionMemoryManager实例加载并映射。下图说明了这个机制。参考<llvm_source>/lib/ExecutionEngine/MCJIT/MCJIT.cpp中的LinkingMemoryManager::getSymbolAddress(),以了解详情。
SectionMemoryManager实例是一个简单的管理器。作为一个RTDyldMemoryManager的子类,SectionMemoryManager继承了它所有的库查询方法,但是通过直接处理低层MemoryBlock单元(<llvm_source>/include/llvm/Support/Memory.h)实现了代码和数据段的分配。
MC代码输出
MCJIT通过调用MCJIT::emitObject()执行MC代码输出。这个方法执行下面的任务:
创建一个PassManager对象。
添加一个目标布局Pass,调用addPassesToEmitMC()以添加所有代码生成Pass和MC代码输出。
利用PassManager::run()方法运行所有的Pass。结果代码存储在一个ObjectBufferStream对象中。
添加已编译的对象到ObjectCache实例并返回它。
MCJIT的代码生成比原先的JIT更一致。不是给JIT提供定制的输出器和目标信息,MCJIT透明地访问存在的MC基础结构的所有信息。
让对象就绪
最终,MCJIT::finalizeLoadedModules()让模块对象就绪:重定向已解决,已加载模块被移到已就绪模块组,调用LinkingMemoryManager::finalizeMemory()以改变内存页面权限。对象就绪之后,MCJIT编译的函数已准备好执行了。
使用MCJIT引擎
下面的sum-mcjit.cpp源文件包含了JIT编译Sum函数所必需的代码,利用MCJIT框架,而不是原先的JIT。为了表明它和前面的JIT例子的相似之处,我们保留了原先的代码,并用布尔变量UseMCJIT来决定使用原先的JIT还是MCJIT。因为代码和前面的sum-jit.cpp相当类似,我们将避免详细介绍前面的例子已经给出的代码片段。
首先,包含MCJIT头文件,如下面的代码所示:
#include "llvm/ExecutionEngine/MCJIT.h"
包含其它必需的头文件,导入llvm名字空间:
#include "llvm/ADT/OwningPtr.h"
#include "llvm/Bitcode/ReaderWriter.h"
#include "llvm/ExecutionEngine/JIT.h"
#include "llvm/IR/LLVMContext.h"
#include "llvm/IR/Module.h"
#include "llvm/Support/MemoryBuffer.h"
#include "llvm/Support/ManagedStatic.h"
#include "llvm/Support/TargetSelect.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/Support/system_error.h"
#include "llvm/Support/FileSystem.h"
using namespace llvm;
将UseMCJIT设置为true,以测试MCJIT。设置为false就用原先的JIT运行这个例子,如下面的代码所示:
bool UseMCJIT = true;
int main() {
InitializeNativeTarget();
MCJIT需要初始化汇编解析器和打印器:
if (UseMCJIT) {
InitializeNativeTargetAsmPrinter();
InitializeNativeTargetAsmParser();
}
LLVMContext Context;
std::string ErrorMessage;
OwningPtr<MemoryBuffer> Buffer;
if (MemoryBuffer::getFile("./sum.bc", Buffer)) {
errs() << "sum.bc not found\n";
return -1;
}
Module *M = ParseBitcodeFile(Buffer.get(), Context, &ErrorMessage);
if (!M) {
errs() << ErrorMessage << "\n";
return -1;
}
创建执行引擎,调用SetUseMCJIT(true)方法,让引擎使用MCJIT,如下面的代码所示:
OwningPtr<ExecutionEngine> EE;
if (UseMCJIT)
EE.reset(EngineBuilder(M).setUseMCJIT(true).create());
else
EE.reset(EngineBuilder(M).create());
原先的JIT需要Function引用,用于以后获取函数指针,销毁分配的内存:
Function* SumFn = NULL;
if (!UseMCJIT)
SumFn = cast<Function>(M->getFunction("sum"));
如前所述,MCJIT淘汰了getPointerToFunction(),在MCJIT中只能用getFunctionAddress()。因此,对于各个JIT类别,要用正确的方法:
int (*Sum)(int, int) = NULL;
if (UseMCJIT)
Sum = (int (*)(int, int)) EE->getFunctionAddress(std::string("sum"));
else
Sum = (int (*)(int, int)) EE->getPointerToFunction(SumFn);
int res = Sum(4, 5);
outs() << "Sum result: " << res << "\n";
res = Sum(res, 6);
outs() << "Sum result: " << res << "\n";
因为MCJIT一次编译整个模块,释放Sum函数的机器代码内存在原先的JIT中才有意义:
if (!UseMCJIT)
EE->freeMachineCodeForFunction(SumFn);
llvm_shutdown();
return 0;
}
要编译和链接sum-mcjit.cpp,用下面的命令:
$ clang++ sum-mcjit.cpp -g -O3 -rdynamic -fno-rtti $(llvm-config --cppflags --ldflags --libs jit mcjit native irreader) -o sum-mcjit
或者,修改第3章(工具和设计)的Makefile。运行这个例子,检验输出:
$ ./sum-mcjit
Sum result: 9
Sum result: 15
使用LLVM JIT编译工具
LLVM提供了一些JIT引擎的工具。lli和llvm-rtdyld就是它们的例子。
使用lli工具
利用这一章学习的LLVM执行引擎,解释工具(lli)实现了一个LLVM bitcode解释器和JIT编译器。考虑下面的源文件,sum-main.c:
#include <stdio.h>
int sum(int a, int b) {
return a + b;
}
int main() {
printf("sum: %d\n", sum(2, 3) + sum(3, 4));
return 0;
}
lli工具能够运行bitcode文件,只要有main函数。用clang生成sum-main.bc bitcode文件:
$ clang -emit-llvm -c sum-main.c -o sum-main.bc
现在,通过lli利用原先的JIT编译引擎运行bitcode:
$ lli sum-main.bc
sum: 12
或者,用MCJIT引擎:
$ lli -use-mcjit sum-main.bc
sum: 12
也有应用解释器的标记,它一般是很慢的:
$ lli -force-interpreter sum-main.bc
sum: 12
使用llvm-rtdyld工具
llvm-rtdyld工具()是一个非常简单的测试MCJIT对象加载和链接框架的工具。它能够从磁盘读取二进制目标文件,执行通过命令行指定的函数。它不作JIT编译和执行,但是让你能够测试和运行目标文件。
考虑下面三个C源代码文件: main.c,add.c,和sub.c:
main.c
int add(int a, int b);
int sub(int a, int b);
int main() {
return sub(add(3, 4), 2);
}
add.c
int add(int a, int b) {
return a+b;
}
sub.c
int sub(int a, int b) {
return a-b;
}
编译它们为目标文件:
$ clang -c main.c -o main.o
$ clang -c add.c -o add.o
$ clang -c sub.c -o sub.o
利用llvm-rtdyld工具执行main函数,以-entry和-execute选项:
$ llvm-rtdyld -execute -entry=_main main.o add.o sub.o; echo $? loaded '_main' at: 0x104d98000
5
另一个选项是,为编译了调试信息的函数打印行信息,它是-printline。举例来说,看下面的命令行:
$ clang -g -c add.c -o add.o
$ llvm-rtdyld -printline add.o
Function: _add, Size = 20
Line info @ 0: add.c, line: 2
Line info @ 10: add.c, line: 3
Line info @ 20: add.c, line: 3
我们看到,llvm-rtdyld工具在实践中运用了MCJIT框架的对象抽象。llvm-rtdyld工具读取一系列二进制目标文件到ObjectBuffer对象,通过RuntimeDyld::loadObject()生成ObjectImage实例。加载所有目标文件之后,由RuntimeDyld::resolveRelocations()解决重定位。接着,通过getSymbolAddress()解决入口点(entry point),并调用函数。
llvm-rtdyld工具用了一个定制的内存管理器,TrivialMemoryManager。这是一个易于理解的简单的RTDyldMemoryManager子类的实现。
这个了不起的概念验证工具让你理解了MCJIT框架涉及的基础概念。
其它的资源
通过在线文档和例子学习LLVM JIT,有其它资源。在LLVM源代码树中,<llvm_source>/examples/HowToUseJIT和<llvm_source>/examples/ParallelJIT包含了简单的源代码例子,可用于学习JIT基础。
LLVM kaleidoscope教程(http://llvm.org/docs/tutorial)有具体的章节介绍如何使用JIT(http://llvm.org/docs/tutorial/LangImpl4.html)。
想了解更多关于MCJIT设计和实现的信息,请查看http://llvm.org/docs/MCJITDesignAndImplementation.html。
总结
JIT编译是一种运行时编译特性,出现于若干虚拟机环境中。在本章中,通过展示两种可得到的截然不同的实现,即原先的JIT和MCJIT,我们探索了LLVM JIT执行引擎。此外,我们考察了两种方案的实现细节,给出了实际的例子来解释如何用JIT引擎编译工具。
在下一章,我们将介绍交叉编译、工具链、以及如何创建基于LLVM的交叉编译器。