第6章 后端
后端(backend)由一套分析和转换Pass组成,它们的任务是代码生成,即将LLVM中间表示(IR)变换为目标代码(或者汇编)。LLVM支持广泛的目标:ARM,AArch64,Hexagon,MSP430,MIPS,Nvidia PTX,PowerPC,R600,SPARC,SystemZ,X86,和XCore。所有这些后端共享一套共用的接口,它是目标无关代码生成器的一部分,以通用API的方法抽象化后端任务。每个目标必须特殊化代码生成通用类,以实现目标特定的行为。在本章中,我们将介绍LLVM后端的多种一般性质,这对于感兴趣的读者来说,无论他想编写一个新的后端,维护一个已有的后端,或者编写一个后端Pass,都是很有用的。我们将介绍以下内容:
LLVM后端的组织结构概述
如何解释各种描述后端的TableGen文件
什么是LLVM指令选择以及如何运作
指令调度和寄存器分配的任务是什么
指令输出如何工作
编写你自己的后端Pass
概述
将LLVM IR转换为目标汇编代码需要经历若干步骤。IR被变换为后端友好的指令、函数、全局变量的表示。这种表示随着程序经历各种后端阶段而变化,越来越接近实际的目标指令。下图给出了必需的步骤的概观,从LLVM IR到目标代码或者汇编,而如白色框所指示的,可以执行非必需的优化Pass以进一步改进翻译的质量。
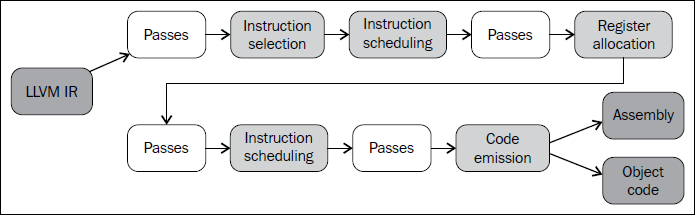
这个翻译流水线由后端的多个阶段组成,它们表示为浅灰色的中间框。它们在内部也称为super pass,因为它们由若干小的Pass实现。它们和白色框的区别在于,前者这些Pass对后端的成功很关键,而后者对于提高所生成的代码的效率更重要。下面我们简略描述上图所说明的代码生成的各个阶段:
指令选择(Instruction Selection)过程将内存中的IR表示变换为目标特定的SelectionDAG节点。起初,这个过程将三地址结构的LLVM IR变换为DAG(Directed Acyclic Graph)形式,这是有向无环图。每个DAG能够表示单一基本块的计算,这意味着每个基本块关联不同的DAG。典型地节点表示指令,而边编码了它们之间的数据流依赖,但不限于此。转换为DAG是重要的,这让LLVM代码生成程序库能够运用基于树的模式匹配指令选择算法,它经过一些调整,也能工作在DAG上(而不仅仅是树)。到这个过程结束时,DAG已将它所有的LLVM IR节点变换为目标机器节点,这些节点表示机器指令而不是LLVM指令。
指令选择之后,对于使用哪些目标指令执行每个基本块的计算,我们已经有了清楚的概念。这编码在SelectionDAG类中。然而,我们需要返回三地址表示形式,以决定基本块内部的指令顺序,因为DAG并不暗示互不依赖的指令之间的顺序。第1次指令调度(Instruction Scheduling),也称为前寄存器分配(RA)调度,对指令排序,同时尝试发现尽可能多的指令层次的并行。然后这些指令被变换为MachineInstr三地址表示。
回想一下,LLVM IR的寄存器集是无限的。这个性质一直保持着,直到寄存器分配(Register Allocation),它将无限的虚拟寄存器的引用转换为有限的目标特定的寄存器集,寄存器不够时挤出(spill)到内存。
第2次指令调度,也称为后寄存器分配(RA)调度,在此时发生。因为此时在这个点可获得真实的寄存器信息,某些类型寄存器存在额外的风险和延迟,它们可被用以改进指令顺序。
代码输出(Code Emission)阶段将指令从MachineInstr表示变换为MCInst实例。这种新的表示更适合汇编器和链接器,它有两种选择:输出汇编代码或者输出二进制块(blob)到一种特定的目标代码格式。
如此,整个后端流水线用到了四种不同层次的指令表示:内存中的LLVM IR,SelectionDAG节点,MachineInstr,和MCInst。
使用后端工具
llc是后端的主要工具。如果我们带着前面一章的sum.bc bitcode继续旅程,我们可以用下面的命令生成它的汇编代码:
$ llc sum.bc -o sum.s
或者生成目标代码,可以用下面的命令:
$ llc sum.bc -filetype=obj -o sum.o
使用以上命令时,llc会尝试选择一个后端匹配sum.bc bitcode中指定的目标三元组。使用-march选项可覆盖它而选择特定的后端。例如,用下面的命令生成MIPS目标代码:
$ llc -march=mips -filetype=obj sum.bc -o sum.o
如果你运行命令llc -version,llc会显示所支持的-march选项的完整列表。注意,这个列表和LLVM配置(详情见第1章,编译和安装LLVM)中用到的–enable-targets选项兼容。
然而要注意的是,我们刚才强制让llc使用一个不同的后端为bitcode生成代码,这个bitcode起初是为x86编译的。在第5章(LLVM中间表示)中,我们解释了IR具有目标相关的一面,尽管它是为所有后端设计的共同语言。因为C/C++语言具有目标相关的属性,所以这种相关性会体现在LLVM IR中。
因此,当bitcode的目标三元组和运行llc -march的目标不匹配时,必须谨慎。这种情况可能会导致ABI不匹配,坏的程序行为,有时还会导致代码生成器失败。然而在大多数情况下,代码生成器不会失败,它生成的代码含有微妙的bug,这是更糟糕的。
为了理解IR的目标依赖性在实践中怎样表现,让我们看一个例子。考虑你的程序分配了char指针的一个vector,用以存储不同的字符串,你用通用的C语句malloc(sizeof(char*)*n)来为字符串vector分配内存。如果你在前端时指定了目标,比如32位MIPS架构,它生成的代码会让malloc分配n x 4字节的内存,因为在32位MIPS上每个指针是4字节。然而,如果你用llc编译这个bitcode而强制指定x86_64架构,它将生成坏的程序。在运行时,会发生潜在的分段错误(segmentation fault),因为x86_64架构的每个指针是8字节,这使得malloc分配的内存不足够。在x86_64上正确的malloc调用将分配n x 8字节。
学习后端代码结构
后端的实现分散在LLVM源代码树的不同目录中。代码生成背后的主要程序库位于lib目录和它的子文件夹CodeGen、MC、TableGen、和Target中:
CodeGen目录包含的文件和头文件实现了所有通用的代码生成算法:指令选择,指令调度,寄存器分配,和所有它们需要的分析。
MC目录实现了低层次功能,包括汇编器(汇编解析器)、松弛算法(反汇编器)、和特定的目标文件格式如ELF、COFF、Macho等等。
TableGen目录包含TableGen工具的完整实现,它可以根据.td文件中的高层次的目标描述生成C++代码。
每个目标的实现在Target的子文件夹中,如Target/Mips,包括若干.cpp、.h、和.td文件。为不同目标实现类似功能的文件倾向于共用类似的名字。
如果你编写一个新的后端,你的代码将仅仅出现在Target文件夹中的一个子文件夹。作为一个例子,我们用Sparc来阐明Target/Sparc子文件夹中的组织:
Filenames |
Description |
|---|---|
SparcInstrInfo.td SparcInstrFormats.td |
Instruction and format definitions |
SparcRegisterInfo.td |
Registers and register classes definitions |
SparcISelDAGToDAG.cpp |
Instruction selection |
SparcISelLowering.cpp |
SelectionDAG node lowering |
SparcTargetMachine.cpp |
Information about target-specific, properties such as the data layout and the ABI |
Sparc.td |
Definition of machine features, CPU variations, and extension features |
SparcAsmPrinter.cpp |
Assembly code emission |
SparcCallingConv.td |
ABI-defined calling conventions |
通常后端都遵从这样的代码组织结构,因此开发者很容易地将一个后端的具体问题映射到另一个后端中。例如,你正在编写Sparc后端的寄存器信息文件SparcRegisterInfo.td,并且想知道x86后端是如何实现它的,你只要查看Target/X86文件夹中的X86RegisterInfo.td文件。
了解后端程序库
llc的非共享代码是相当小的(见tools/llc/llc.cpp),其大部分功能被实现为可重用的库,如同其它LLVM工具。对于llc的情况,它的功能由代码生成的库提供。这组程序库可分成目标相关的部分和目标无关的部分。代码生成的目标相关的库和目标无关的库在不同的文件中,这让你能够链接所期望的有限的目标后端。例如,在配置LLVM的时候设置–enable-targets=x86, arm,这样llc就只会链接x86和ARM的后端程序库。
回想所有的LLVM程序库都以libLLVM为前缀。为清楚起见,我们在此省略这个前缀。下面列出了目标无关的代码生成器程序库:
AsmParser.a:这个库包含解析汇编文本的代码,实现了一个汇编器
AsmPrinter.a:这个库包含打印汇编语言的代码,实现了一个生成汇编文件的后端
CodeGen.a:这个库包含代码生成算法
MC.a:这个库包含MCInst类及其相关的类,用于以LLVM允许的最低层级表示程序
MCDisassembler.a:这个库实现了一个反汇编器,它读取目标代码文件,将字节解码为MCInst对象
MCJIT.a:这个库实现了just-in-time(即时)代码生成器
MCParser.a:这个库包含导出MCAsmParser类的接口,用于实现解析汇编文本的组件,执行汇编器的部分工作
SelectionDAG.a:这个库包含SelectionDAG及其相关的类
Target.a:这个库包含的接口能够让目标无关的算法请求目标相关的功能,尽管此功能实质上是由其它库(目标相关部分)实现的
另一方面,下面是目标特定的程序库:
<Target>AsmParser.a:这个库包含AsmParser库的目标特定的部分,负责为目标机器实现汇编器
<Target>AsmPrinter.a:这个库包含打印目标指令的功能,让后端能够生成汇编语言文件
<Target>CodeGen.a:这个库包含后端目标相关功能的主体,包括具体的寄存器处理规则、指令选择、和调度
<Target>Desc.a:这个库包含关于低层级MC设施的目标机器信息,负责注册目标特定的MC对象,例如MCCodeEmitter
<Target>Disassembler.a:这个库补足了MCDisassembler库的目标相关的功能,以建造一个能够读取字节并将它们解码成MCInst目标指令的系统
<Target>Info.a:这个库负责在LLVM代码生成器系统中注册目标,提供了让目标无关的代码生成器程序库能够访问目标特定功能的门面类。
在这些库的名字中,<Target>必须被替换为目标名字,例如,X86AsmParser.a是X86后端的解析程序库的名字。完整的LLVM安装将包含这些库,在<LLVM_INSTALL_PATH>/lib目录中。
学习LLVM后端如何利用TableGen
LLVM使用记录导向语言TableGen来描述若干编译器阶段用到的信息。例如,在第4章(前端)中,我们简单讨论了如何用TableGen文件(以.td为扩展名)描述前端的不同诊断信息。最初,LLVM团队开发TableGen是为了帮助程序员编写LLVM后端的。尽管代码生成器程序库的设计强调清楚地分离不同的目标特性,例如,用不同的class表示寄存器信息和指令,但是最终后端程序员写出的代码不得不在若干不同的文件中表示相同的某种机器特征。这种方法的问题在于,不仅付出额外的努力编写后端代码,而且在代码中引入了信息冗余,必须手工同步。
例如,你想修改后端如何处理一个寄存器,将需要修改代码中几处不同的部分:在寄存器分配器中说明支持哪些寄存器类型;在汇编打印器中体现如何打印这个寄存器;在汇编解析器中体现它在汇编语言代码中如何解析;以及在反汇编器中,它需要知道寄存器的编码方式。这样,维护一个后端的代码变得很复杂。
为了减轻这种复杂性,人们创造了TableGen,它对描述文件来说是一种声明式编程语言,这些文件成为关于目标的中央信息库。其想法是这样的:在一个单一位置声明机器的某种特性,例如在<Target>InstrInfo.td中描述机器指令,然后TableGen后端用这个信息库去达成一个具体的目的,例如生成模式匹配指令选择算法,这个算法你自己编写的话是很冗长乏味的。
如今,TableGen被用于描述所有种类的目标特定的信息,如指令格式、指令、寄存器、模式匹配DAG、指令选择匹配顺序、调用惯例、和目标CPU属性(支持的指令集架构(ISA)特征和处理器族)。
备注
在计算机架构研究领域,完全自动地为处理器生成后端、模拟器、和硬件综合描述文件已经成为一个长期追求的目标,并且仍然是一个开放的问题。典型的方法是用一个类似TableGen的声明描述语言表示所有的机器信息,然后利用工具派生出所需要的各种软件(和硬件),并评估、测试处理器架构。如同期望的那样,这是非常困难的,和手工编写的工具相比,自动生成的工具的质量不尽如人意。LLVM TableGen的方法是辅助程序员完成较小的代码编写任务,仍然给予程序员完整的控制权,让他们用C++代码来实现任意定制的逻辑。
语言
TableGen语言由定义和类(class)组成,它们用于建立记录。定义def用于根据class和multiclass关键字实例化记录。这些记录由TableGen后端进一步处理,为以下部件生成域特定的信息:代码生成器、Clang诊断、Clang驱动器选项、和静态分析器检查器。因此,记录所表示的实际意思由后端给出,而记录仅仅存放信息。
让我们示范一个简单的例子来阐述TableGen如何工作。假设你想为一个假设的架构定义ADD和SUB指令,而ADD有以下两种形式:所有操作数都是寄存器,操作数一个是寄存器一个是立即数。
SUB指令只有第1种形式。看下面insns.td文件的示例代码:
class Insn<bits <4> MajOpc, bit MinOpc> {
bits<32> insnEncoding;
let insnEncoding{15-12} = MajOpc;
let insnEncoding{11} = MinOpc;
}
multiclass RegAndImmInsn<bits <4> opcode> {
def rr : Insn<opcode, 0>;
def ri : Insn<opcode, 1>;
}
def SUB : Insn<0x00, 0>;
defm ADD : RegAndImmInsn<0x01>;
Insn class表示一个常规指令,RegAndImmInsn multiclass表示上面所提到的形式的指令。def SUB定义了SUB记录,而defm ADD定义了两个记录:ADDrr和ADDri。利用llvm-tblgen工具,你可以处理一个.td文件并检查结果记录:
$ llvm-tblgen -print-records insns.td
------------- Classes -----------------
class Insn<bits<4> Insn:MajOpc = { ?, ?, ?, ? }, bit Insn:MinOpc = ?> {
bits<5> insnEncoding = { Insn:MinOpc, Insn:MajOpc{0},
Insn:MajOpc{1}, Insn:MajOpc{2}, Insn:MajOpc{3} };
string NAME = ?;
}
------------- Defs -----------------
def ADDri { // Insn ri
bits<5> insnEncoding = { 1, 1, 0, 0, 0 };
string NAME = "ADD";
}
def ADDrr { // Insn rr
bits<5> insnEncoding = { 0, 1, 0, 0, 0 };
string NAME = "ADD";
}
def SUB { // Insn
bits<5> insnEncoding = { 0, 0, 0, 0, 0 };
string NAME = ?;
}
通过llvm-tblgen工具还可使用TableGen后端;输入llvm-tblgen –help,会列出所有后端选项。注意此例子没有用LLVM特定的域,它不能用于一个后端。关于TableGen语言的更多信息,请参考网页http://llvm.org/docs/TableGenFundamentals.html。
了解代码生成器.td文件
如前所述,代码生成器广泛地使用TableGen记录来表达目标特定的信息。在这个子小节,我们来浏览一下致力于代码生成的TableGen文件。
目标属性
<Target>.td文件(例如,X86.td)定义了所支持的ISA特性和处理器家族。例如,X86.td定义了AVX2扩展:
def FeatureAVX2 : SubtargetFeature<”avx2”, “X86SSELevel”, “AVX2”,
“Enable AVX2 instructions”,
[FeatureAVX]>;
关键字def通过class类型SubtargetFeature定义了记录FeatureAVX2。最后一个参数是已经包含在定义中的其它特性的一个列表。因此,一个具有AVX2的处理器包含所有AVX指令。
此外,我们还可以定义一个处理器类型,包含它所能提供的ISA扩展和特性:
def : ProcessorModel<”corei7-avx”, SandyBridgeModel,
[FeatureAVX, FeatureCMPXCHG16B, ...,
FeaturePCLMUL]>;
<Target>.td文件还包含了所有其它的.td文件,是描述目标特定域信息的主文件。llvm-tblgen工具必须总是从它那获得一个目标任意的TableGen记录。例如,为了输出x86所有可能的记录,执行下面的命令:
$ cd <llvm_source>/lib/Target/X86
$ llvm-tblgen -print-records X86.td -I ../../../include
X86.td文件含有TableGen用以生成X86GenSubtargetInfo.inc文件的部分信息,但是所用的信息不限于此,一般来说,没有从一个.td文件到一个.inc文件的直接映射。为了理解这个表述,考虑<Target>.td文件是一个重要的顶层文件,它利用TableGen的include指令包含了所有其它的.td文件。因此,当生成C++代码时,TableGen总是解析所有的后端.td文件,这意味着你可以自由地将记录放到任意你觉得最合适的地方。即使X86.td包含了所有其它的后端.td文件,除了include指令,这个文件的内容也是和Subtarget x86子类的定义保持一致的。
如果你查看实现x86Subtarget类的X86Subtarget.cpp文件,你会发现一个C++预处理器指令,”#include “X86GenSubtargetInfo.inc”,这揭示了我们如何在常规的code base中嵌入TableGen生成的C++代码。这个特别的include文件包含了处理器特性常量,处理器特性向量——它关联了特性和它的字符串描述,以及其它相关的资源。
寄存器
寄存器和寄存器类在<Target>RegisterInfo.td文件中定义。寄存器类用于在之后的指令定义中连结指令操作数和特定的寄存器集合。例如,X86RegisterInfo.td用下面的语句定义了16位的寄存器:
let SubRegIndices = [sub_8bit, sub_8bit_hi], ... in {
def AX : X86Reg<"ax", 0, [AL,AH]>;
def DX : X86Reg<"dx", 2, [DL,DH]>;
def CX : X86Reg<"cx", 1, [CL,CH]>;
def BX : X86Reg<"bx", 3, [BL,BH]>;
...
此处let构建指令用于定义一个额外的字段SubRegIndices,在以{开始并以}结束的区域中的所有记录都会存放这个字段。16位的寄存器的定义是从X86Reg类派生而来的,它为每个寄存器保存它的名字、数目、和一个8位的子寄存器的列表。16位寄存器的寄存器类的定义被重新产生,如下所示:
def GR16 : RegisterClass<"X86", [i16], 16,
(add AX, CX, DX, ..., BX, BP, SP,
R8W, R9W, ..., R15W, R12W, R13W)>;
GR16寄存器类包含所有的16位寄存器和它们各自的寄存器分配首选的顺序。在TableGen处理之后,每个寄存器类的名字会得到后缀RegClass,例如,GR16变成了GR16RegClass。TableGen会生成寄存器和寄存器类的定义,收集它们的相关信息的方法,汇编器的二进制编码,和它们的DWARF(Linux调试记录格式)信息。你可以用llvm-tblgen查看TableGen生成的代码:
$ cd <llvm_source>/lib/Target/X86
$ llvm-tblgen -gen-register-info X86.td -I ../../../include
可选地,你可以查看LLVM编译过程中生成的C++文件<LLVM_BUILD_DIR>/lib/Target/X86/X86GenRegisterInfo.inc。这个文件被X86RegisterInfo.cpp包含,辅助它定义X86RegisterInfo类。其中包含了处理器寄存器的枚举,当你在调试你的后端并且不知道数字16表示什么寄存器(这是你的调试器所能给你的最好的猜测)的时候,这个文件是一份有用的参考指引。
指令
指令格式和指令分别在<Target>InstrFormats.td和<Target>InstInfo.td文件中被定义。指令格式包含所必需的指令编码字段,用于写二进制形式的指令,而指令记录表示指令,一条记录表示一条指令。你可以创建中间指令类,就是用于派生指令记录的TableGen类,以析出公共特性因子,例如相似的数据处理指令的共同编码方式。然而,每个指令或者格式必须是Instruction TableGen类的直接或间接的子类,Instruction类在include/llvm/Target/Target.td中被定义。它的字段显示了TableGen后端期望在指令记录中找到什么内容:
class Instruction {
dag OutOperandList;
dag InOperandList;
string AsmString = "";
list<dag> Pattern;
list<Register> Uses = [];
list<Register> Defs = [];
list<Predicate> Predicates = [];
bit isReturn = 0;
bit isBranch = 0;
...
dag是一种特别的TableGen类型,用于存放SelectionDAG节点。这些节点表示指令选择过程的操作符、寄存器、或常量。代码中出现的字段扮演如下角色:
OutOperandList字段存储结果节点,让后端能够找到代表指令输出的DAG节点。例如,在MIPS ADD指令中,这个字段被定义为(outs GP32Opnd:$rd)。在此例中:
outs是一个特别的DAG节点,用于指示它的孩子是输出操作数
GPR32Opnd是一个MIPS专有的DAG节点,用于指示MIPS 32位的通用寄存器的一个实例
$rd是一个任意的寄存器名字,用于识别节点
InOperandList字段存放输入节点,例如,在MIPS ADD指令中,它是(ins GRP32Opnd:$rs, GRP32Opnd:$rt)。
AsmString字段表示指令的汇编字符串,例如,在MIPS ADD指令中,它是”add $rd, $rs, $rt”。
Pattern是dag对象的列表,它将在指令选择时被用于执行模式匹配。如果一个模式被匹配了,指令选择过程会用这条指令替换匹配的节点。例如,在MIPS ADD指令的[(set GPR32Opnd:$rd, (add GPR32Opnd:$rs, GPR32Opns:$rt))]模式中,[ and ]表示只有一个dag元素的列表的内容,它是在类似LISP表示法的小括号之间被定义的。
Uses和Defs记录在指令执行期间被隐式使用和定义的寄存器的列表。例如,RISC处理器的return指令隐式地返回地址寄存器,而call指令隐式地定义返回地址寄存器。
Predicates字段存储在指令选择尝试匹配指令之前要检查的先决条件的列表。如果检查失败了,就没有匹配。例如,一个predicate可能说明这个指令只对特定的子目标有效。如果你所运行代码生成器的目标三元组选择了另一个子目标,这个predicate会评估为假,这个指令永远不会匹配。
此外,其它的字段包括isReturn和isBranch,它们向代码生成器说明关于指令行为的信息。例如,如果isBranch = 1,代码生成器就知道这个指令是分支指令,必须处在一个基本块的末尾。
在下面的代码块中,我们看到在SparcInstrInfo.td中的XNORrr指令的定义。它用到了F3_1格式(在SparcInstrFormats.td中被定义),它包括了来自SPARC V8架构手册的F3格式的一部分:
def XNORrr : F3_1<2, 0b000111,
(outs IntRegs:$dst), (ins IntRegs:$b, IntRegs:$c),
"xnor $b, $c, $dst",
[(set i32:$dst, (not (xor i32:$b, i32:$c)))]>;
这个XNORrr指令有两个IntRegs(一个表示SPARC 32位整数寄存器类的目标特定的DAG节点)源操作数和一个IntRegs结果,也就是OutOperandList = (outs IntRegs:$dst)和InOperandList = (ins IntRegs:$b, IntRegs:$c)。
AsmString汇编通过$记号引用指定的操作数:”xnor $b, $c, $dst”。Pattern列表元素包含那个SelectionDAG节点,它应该被匹配到这个指令。举例来说,每当xor的结果由一个not反转位,并且xor的两个操作数都是寄存器的时候,XNORrr指令被匹配。
为了查看XNORrr指令记录的字段,你可以执行下面的命令序列:
$ cd <llvm_sources>/lib/Target/Sparc
$ llvm-tblgen -print-records Sparc.td -I ../../../include | grep XNORrr -A 10
多个TableGen后端利用指令记录的信息以履行它们的职能,从相同的指令记录生成不同的.inc文件。这跟TablenGen的目标是一致的,即创建一个中央仓库,利用它给后端的各个部分生成代码。下面的每个文件是由不同的TableGen后端生成的:
<Target>GenDAGISel.inc:这个文件利用指令记录中patterns字段的信息以输出选择SelectionDAG数据结构的指令的代码。<Target>ISelDAGtoDAG.cpp文件包含这个文件。
<Target>GenInstrInfo.inc:这个文件包含列出目标的所有指令的枚举,除了其它的描述指令的表。<Target>InstrInfo.cpp、<Target>InstrInfo.h、<Target>MCTargetDesc.cpp、和<Target>MCTargetDesc.h包含这个文件。然而,每个文件会在包含TableGen生成的文件之前定义一组特定的宏,改变了这个文件如何在每个上下文中被解析和使用。
<Target>GenAsmWriter.inc:这个文件包含映射字符串的代码,该字符串被用来打印每个指令的汇编。<Target>AsmPrinter.cpp文件包含这个文件。
<Target>GenCodeEmitter.inc:这个文件包含这样的函数,它们为每条指令映射并输出二进制代码,从而生成机器代码以填写目标文件。<Target>CodeEmitter.cpp包含这个文件。
<Target>GenDisassemblerTables.inc:这个文件实现这样的表和算法,它们能够解码一个字节序列并识别出它表示的目标指令。它用于实现反汇编工具,<Target>Disassembler.cpp文件包含它。
<Target>GenAsmMatcher.inc:这个文件实现目标指令的汇编器的解析器。<Target>AsmParser.cpp文件包含它两次,每次都有一组不同的预处理宏,从而改变如何解析这个文件。
理解指令选择过程
指令选择是将LLVM IR转换为代表目标指令的SelectionDAG节点(SDNode)的过程。第一步是根据LLVM IR指令建立DAG,创建SelectionDAG对象,其节点保存IR操作。接着,这些节点经过低层化、DAG结合、和合法化等过程,使它更容易匹配目标指令。然后,指令选择用节点模式匹配方法执行DAG到DAG的变换,将SelectionDAG节点转换为代表目标指令的节点。
备注
指令选择是其中一个最耗时的后端Pass。一项编译SPEC CPU2006基准测试的函数的研究揭示,在LLVM 3.0中,以-O2运行llc工具,平均来说,指令选择Pass几乎花去一半的时间。如果你有兴趣了解所有-O2级别的目标无关和目标有关的Pass的平均占用时间,你可以查看LLVM JIT编译成本分析的技术报告的附件:http://www.ic.unicamp.br/~reltech/2013/13-13.pdf。
SelectionDAG类
SelectionDAG类(class)用一个DAG表示每个基本块的计算,每个SDNode对应一个指令或者操作数。下图由LLVM生成,展示了sum.bc的DAG,它只有一个函数和一个基本块:
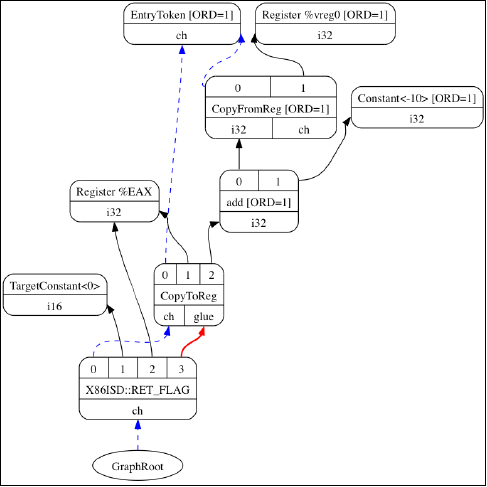
DAG的连线(edge)通过use-def关系强制它的操作之间的顺序。如果节点B(例如,add)有一条出去的连线到节点A(例如,Constant<-10>),这意味着节点A定义了一个值(32位整数-10),而节点B使用它(作为加法的一个操作数)。因此,A操作必须在B之前执行。黑色箭头表示常规连线,指示数据流依赖,正如例子add。虚线蓝色箭头表示非数据流链,用以强制两条指令的顺序,否则它们就是不相关的,例如,load和store指令必须固定它们原始的程序顺序,如果它们访问相同的内存位置。在前面的图中,我们知道CopyToReg操作必须在X86ISD::RET_FLAG之前发生,由于虚线蓝色箭头。红色连线保证它相邻的节点必须粘合在一起,这意味着它们必须紧挨着执行,它们之间不可有其它指令。例如,我们指定相同的节点CopyToReg和X86ISD::RET_FLAG必须安排为紧挨着,由于红色的连线。
每个节点可以提供一个不同的值类型,依赖于它和它的使用者的关系。一个值不必是具体的,也可能是一个抽象的标记(token)。它可能有任意如下类型:
节点所提供的值可以是一个具体的值类型,表示整数、浮点数、向量、或指针。数据处理节点根据它的操作数计算一个新的值,其结果是这种类别的一个例子。类型可以是i32、i64、f32、v2f32(有两个f32元素的向量)、和iPTR等。在LLVM示意图中,当另一个节点使用这个值的时候,生产者-消费者关系是由一条常规的黑色连线描绘的。
Other类型是一个抽象的标记,用于表示链值(示意图中的ch)。在LLVM示意图中,当另一个节点使用一个Other类型的值的时候,连接两者的连线被打印为蓝色的虚线。
Glue类型表示粘合。在LLVM示意图中,当另一个节点使用一个Glue类型的值的时候,连接两者的连线被画成红色。
SelectionDAG对象有一个特别的标记基本块入口的EntryToken,它提供一个Other类型的值,让成链的节点能够以它为起点。SelectionDAG对象还会引用图的根节点,这个根节点正好是最后一条指令的后续节点,它们的关系也被编码为Other类型的值的一个链。
在这个阶段,目标无关和目标特定的节点可以同时存在,这是执行预备步骤的结果,例如低层化和合法化,这些预备步骤负责为指令选择准备DAG。然而,等到指令选择结束的时候,所有被目标指令匹配的节点都会是目标特定的。在前面的示意图中,有如下目标无关的节点:CopyToReg,CopyFromReg,Register (%vreg0),add,和Constant。此外,有如下已经被预处理并且是目标特定的节点(尽管它们在指令选择之后仍然可以改变):TargetConstant,Register (%EAX),和X86ISD::REG_Flag。
在示意图所示的例子中,我们可能观察到下面的语义:
Register:这个节点可能引用虚拟或者(目标特定的)物理的寄存器。
CopyFromReg:这个节点复制一个在当前基本块作用域之外定义的寄存器——在我们的例子中,它复制了一个函数的参数。
CopyToReg:这个节点将一个值复制到一个特定的寄存器,可是不提供任何具体的值让其它节点使用它。然而,这个节点产生一个链的值(Other类型),和不生成具体的值的其它节点构成链。举例来说,为了使用被写到EAX的值,X86ISD::RET_FLAG节点使用由Register (%EAX)提供的i32结果,并且还接收由CopyToReg产生的链,这样确保%EAX是通过CopyToReg更新了的,因为这个链会强制CopyToReg被安排在X86ISD::RET_FLAG之前。
想要深入了解SelectionDAG类的细节,请参考llvm/include/llvm/CodeGen/SelectionDAG.h头文件。对于节点的结果类型,你应该参考llvm/include/llvm/CodeGen/ValueTypes.h头文件。头文件llvm/include/llvm/CodeGen/ISDOpcodes.h定义了目标无关的节点,而头文件lib/Target/<Target>/<Target>ISelLowering.h定义了目标特定的节点。
低层化
在前面的子小节中,我们展示的图中目标特定的和目标无关的节点是并存的。你可能会问自己,一些目标特定的节点怎么已经在SelectionDAG中了,如果这是指令选择的输入?为了理解这个问题,我们首先在下图中给出所有先于指令选择的步骤的全局图,在左上角从LLVM IR步骤开始:
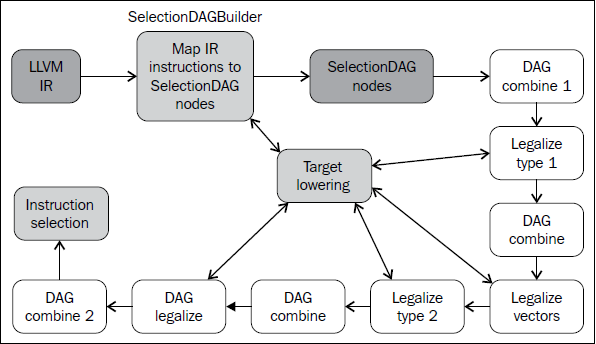
首先,一个SelectionDAGBuilder实例(详情见SelectionDAGISel.cpp)访问每个函数,为每个基本块创建一个SelectionDAG对象。在此过程期间,一些特殊的IR指令例如call和ret已经要求目标特定的语句——例如,如何传递调用参数和如何从一个函数返回——被转换为SelectionDAG节点。为了解决这个问题,TargetLowering class中的算法第一次被使用。这个class是每个目标都必须实现的抽象接口,但是还有大量共用的功能被所有后端所使用。
为了实现这个抽象接口,每个目标声明一个TargetLowering的子类,命名为<Target>TargetLowering。每个目标还重载方法,它们实现一个具体的目标无关的高层次的节点应该如何被低层化到一个层次,它接近这个机器的节点。如期望那样,仅有小部分节点必须以这种方式低层化,而大部分其它节点在指令选择时被匹配和替换。例如,在sum.bc的SelectionDAG中,用X86TargetLowering::LowerReturn()方法(参见lib/Target/X86/X86ISelLowering.cpp)低层化ret IR指令。同时,生成了X86ISD::RET_FLAG节点,它将函数结果复制到EAX——一种处理函数返回的目标特定的方式。
DAG结合与合法化
从SelectionDAGBuilder输出的SelectionDAG并不能直接作指令选择,必须经历附加的转换——如前面图中所显示的。先于指令选择执行的Pass序列如下:
DAG结合Pass优化欠优化的SelectionDAG结构,通过匹配一系列节点并用简化的结构替换它们,当可获利时。例如,子图(add (Register X), (constant 0))可以合并为(Register X)。类似地,目标特定的结合方法可以识别节点模式,并决定结合合并它们是否将提高此目标的指令选择的质量。你可以在lib/CodeGen/SelectionDAG/DAGCombiner.cpp文件中找到LLVM通用的DAG结合的实现,在lib/Target/<Target_Name>/<Target>ISelLowering.cpp文件中找到目标特定的结合的实现。方法setTargetDAGCombine()标记目标想要结合的节点。举例来说,MIPS后端尝试结合加法——见lib/Target/Mips/MipsISelLowering.cpp中的setTargetDAGCombine(ISD::ADD)和performADDCombine()。
备注
DAG结合在每次合法化之后运行,以最小化任何SelectionDAG冗余。而且,DAG结合知道在Pass链的何处运行,(例如在类型合法化或者向量合法化之后),能够运用这些信息以变得更精确。
类型合法化Pass确保指令选择只需要处理合法的类型。合法的类型是指目标天然地支持的类型。例如,在只支持i32类型的目标上,i64操作数的加法是非法的。在这种情况下,类型合法化动作整数展开把i64操作数破分为两个i32操作数,同时生成合适的节点以操作它们。目标定义了每种类型所关联的寄存器,显式地声明了支持的类型。这样,非法的类型必须被删除并相应地处理:标量类型可以被提升,展开,或者软件化,而向量类型可以被分解,标量化,或者放宽——见llvm/include/llvm/Target/TargetLowering.h对每种情况的解释。此外,目标还可以设置定制的方法来合法化类型。类型合法化运行两次,在第一次DAG结合之后和在向量合法化之后。
有的时候,后端直接支持向量类型,这意味着有一个这样的寄存器类,但是没有处理给定向量类型的具体的操作。例如,x86的SSE2支持v4i32向量类型。然而,并没有x86指令支持v4i32类型的ISD::OR操作,而只有v2i64的。因此,向量合法化会处理这种情况,提升或者扩展操作,为指令使用合法的类型。目标还可以通过定制的方式处理合法化。对于前面提到的ISD::OR,操作会被提升而使用v2i64类型。看一看下面的lib/Target/X86/X86ISelLowering.cpp的代码片段:
setOperationAction(ISD::OR, v4i32, Promote);
AddPromotedToType (ISD::OR, v4i32, MVT::v2i64);
备注
对于某些类型,扩展会消除向量而使用标量。这可能引入目标不支持的标量类型。然而,后续的类型合法化会清理这种情况。
DAG合法化扮演向量合法化一样的角色,但是它处理任意剩余的具有不支持的类型(标量或向量)的操作。它支持相同的动作:提升、扩展、和定制节点的处理。举例来说,x86不支持以下三种情形:i8类型的有符号整数到浮点数的转化操作(ISD::SINT_TO_FP),请求合法化提升它;i32操作数的有符号除法(ISD::SDIV),发起一个扩展请求,产生一个库调用以处理这个除法;f32操作数的浮点数绝对值,利用定制的句柄生成具有相同效果的等价的代码。x86以如下方式发起这些动作(参见lib/Target/X86/X86ISelLowering.cpp):
setOperationAction(ISD::SINT_TO_FP, MVT::i8, Promote);
setOperationAction(ISD::SDIV, MVT::i32, Expand);
setOperationAction(ISD::FABS, MVT::f32, Custom);
DAG到DAG的指令选择
DAG到DAG的指令选择的目的,是利用模式匹配将目标无关的节点转换为目标特定的节点。指令选择的算法是局部的,每次作用SelectionDAG(基本块)的实例。
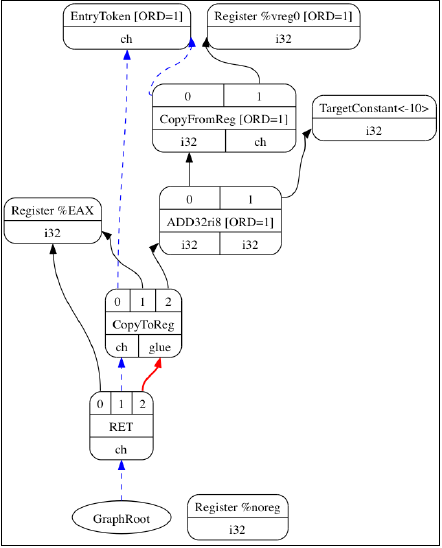
作为例子,后面给出了指令选择之后我们最终的SelectionDAG结构。CopyToReg、CopyFromReg、和Register节点保持不变,直到寄存器分配。实际上,指令选择过程甚至可能增加节点。指令选择之后,ISD::ADD节点被转换为X86指令ADD32ri8,X86ISD::RET_FLAG变为RET。
备注
注意,三种指令表示类型可能在同一个DAG中并存:通用的LLVM ISD节点比如ISD::ADD,目标特定的<Target>ISD节点比如X86ISD::REG_FLAG,目标物理指令比如X86::ADD32ri8。
模式匹配
每个目标都有SelectionDAGISel子类,命名为<Target_Name>DAGToDAGISel。它通过实现子类的Select方法来处理指令选择。例如SPARC中的SparcDAGToDAGISel::Select()(参见lib/Target/Sparc/SparcISelDAGToDAG.cpp文件)。这个方法接收将要被匹配的SDNode参数,返回一个代表物理指令的SDNode值;否则发生一个错误。
Select()方法允许用两种方式来匹配物理指令。最直接的方式是调用产生自TableGen模式的匹配代码,如下面列表中的步骤一。然而,模式可能表达不够清楚,使得有些指令的奇怪行为不能被处理。这种情况下,必须在这个方法中实现定制的C++匹配逻辑,如下面列表中的步骤二。下面详细介绍这两种方式:
Select()方法调用SelectCode()。TableGen为每个目标生成SelectCode()方法,在此代码中,TableGen还生成MatcherTable,它将ISD和<Target>ISD映射为物理指令节点。这个匹配器表是从.td文件(通常为<Target>InstrInfo.td)中的指令定义生成的。SelectCode()方法以调用SelectCodeCommon()结束,这是一个目标无关的方法,它根据目标的匹配器表匹配节点。TableGen有一个专门的指令选择后端,用以生成这些方法和表:
$ cd <llvm_source>/lib/Target/Sparc
$ llvm-tblgen -gen-dag-isel Sparc.td -I ../../../include
为每个目标的输出在<build_dir>/lib/Target/<Target>/<Target>GenDAGISel.inc C++文件中;例如,在SPARC中,可在<build_dir>/lib/Target/Sparc/SparcGenDAGISel.inc文件中获得这些方法和表。
Select()方法中在SelectCode调用前提供定制的匹配代码。例如,i32节点ISD::MULHU执行两个i32的乘,产生一个i64结果,并返回高i32部分。在32位SPARC上,乘法指令SP::UMULrr在特殊寄存器Y中返回高位部分,它需要由SP::RDY指令读取它。TableGen无法表达这个逻辑,但是我们可以用下面的代码解决这个问题:
case ISD::MULHU: {
SDValue MulLHS = N->getOperand(0);
SDValue MulRHS = N->getOperand(1);
SDNode *Mul = CurDAG->getMachineNode(SP::UMULrr, dl, MVT::i32, MVT::Glue, MulLHS, MulRHS);
return CurDAG->SelectNodeTo(N, SP::RDY, MVT::i32, SDValue(Mul, 1));
}
这里,N是待匹配的SDNode参数,在此上下文中,N等于ISD::MULHU。因为在这个case语句之前已经作了细致的检查,这里生成SPARC特定的opcode以替换ISD::MULHU。为此,我们通过调用CurDAG->getMachineNode()以SP::UMULrr创建一个物理指令节点。接着,通过CurDAG->SelectNodeTo(),我们创建一个SP::RDY指令节点,并将指向ISD::MULHU的结果的所有use(引用)改变为指向SP::RDY的结果。下图显示了这个例子指令选择前后的SelectionDAG结构。前面的C++代码片段是lib/Target/Sparc/SparcISelDAGToDAG.cpp中的代码的简化版本。
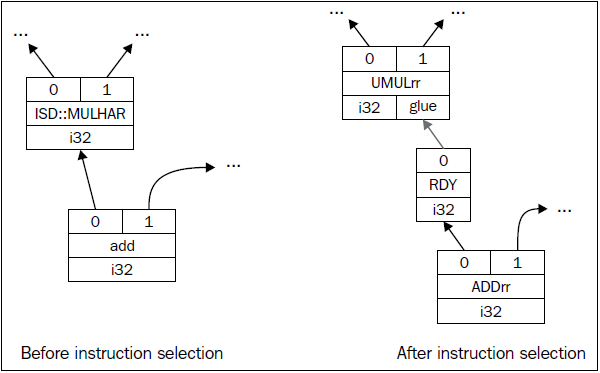
可视化指令选择过程
若干llc的选项可以在不同的指令选择过程可视化SelectionDAG。如果你使用了这些选项中的任意一个,llc将生成一个.dot图,类似于本章早前展示的那样,但是你需要用dot程序来显示它,或者用dotty编辑它。你可以在www.graphviz.org的Graphviz包中找到它们。下图按照执行的顺序列出了每个选项:
llc选项 |
过程 |
|---|---|
-view-dag-combine1-dags |
DAG结合-1之前 |
-view-legalize-types-dags |
类型合法化之前 |
-view-dag-combine-lt-dags |
类型合法化-2之后DAG结合之前 |
-view-legalize-dags |
合法化之前 |
-view-dag-combine2-dags |
DAG结合-2之前 |
-view-isel-dags |
指令选择之前 |
-view-sched-dags |
指令选择之后指令调度之前 |
快速指令选择
LLVM还支持可选的指令选择实现,称为快速指令选择(FastISel class,位于<llvm_source>/lib/CodeGen/SelectionDAG/FastISel.cpp文件)。快速指令选择的目标是快速生成代码,以损失代码质量为代价,它适合-O0优化级别的编译哲学。通过省略复杂的合并和低级化逻辑,编译得到提速。TableGen描述也被用于简单的操作,但是更复杂的指令匹配需要目标特定的代码来处理。
备注
-O0管线编译还用到了快速但非优化的寄存器分配器和调度器,以代码质量换取编译速度。我们将在下一个子小节阐述它们。
调度
指令选择之后,SelectionDAG结构的节点表示了物理指令——处理器直接支持它们。下一个阶段是前寄存器分配调度器,工作在SelectionDAG节点(SDNode)之上。有几个不同的调度器可供选择,它们都是ScheduleDAGSDNodes的子类(见文件<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGSDNodes.cpp)。在llc工具中可以通过-pre-RA-sched=<scheduler>选项选择调度器类型。可能的<scheduler>值如下:
list-ilp,list-hybrid,source,和list-burr:这些选项指定表调度算法,它由ScheduleDAGRRList class实现(见文件<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGRRList.cpp)。fast:ScheduleDAGFast class(<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGFast.cpp)实现了一个非优化但快速的调度器。view-td:一个VLIW特定的调度器,由ScheduleDAGVLIW class实现(见文件<llvm_source>/lib/CodeGen/SelectionDAG/ScheduleDAGVLIW.cpp)。
default选项为目标选择一个预定义的最佳的调度器,而linearize选项不作调度。可获得的调度器可能使用指令行程表和风险识别器的信息,以更好地调度指令。
备注
在代码生成器中有三个不同的调度器:两个在寄存器分配之前,一个在寄存器分配之后。第一个工作在SelectionDAG节点之上,而其它两个工作在机器指令之上,本章将进一步解释它们。
指令延迟表
有些目标提供了指令行程表,表示指令延迟和硬件管线信息。调度器在作调度决策时利用这些属性以最大化吞吐量,避免性能处罚。这些信息由每个目标目录中的TableGen文件,通常命名为<Target>Schedule.td(例如X86Schedule.td)。
LLVM提供了ProcessorItineraries TableGen class,在<llvm_source>/include/llvm/Target/TargetItinerary.td,如下:
class ProcessorItineraries<list<FuncUnit> fu, list<Bypass> bp,
list<InstrItinData> iid> {
...
}
目标可能为一个芯片或者处理器家族定义处理器行程表。要描述它们,目标必须提供函数单元(FuncUnit)列表、管线支路(Bypass)、和指令行程数据(InstrItinData)。例如,ARM Cortex A8指令的行程表在<llvm_source>/lib/Target/ARM/ARMScheduleA8.td,如下
def CortexA8Itineraries : ProcessorItineraries<
[A8_Pipe0, A8_Pipe1, A8_LSPipe, A8_NPipe, A8_NLSPipe],
[], [
...
InstrItinData<IIC_iALUi ,[InstrStage<1, [A8_Pipe0, A8_Pipe1]>], [2, 2]>,
...
]>;
这里,我们没有看到支路(bypass)。我们看到了这个处理器的函数单元列表(A8_Pipe0,A8_Pipe1等),以及来自类型IIC_iALUi的指令行程数据。这种类型是形如reg = reg + immediate的二元运算指令的class,例如ADDri和SUBri指令。这些指令的执行时间是一个机器时钟周期,以完成A8_Pipe0和A8_Pipe1函数单元,如InstrStage<1, [A8_Pipe0, A8_Pipe1]定义的那样。
后面,列表[2, 2]表示指令发射之后读取或者定义每个操作数所用的时钟周期。此处,目标寄存器(index 0)和源寄存器(index 1)都在2个时钟周期之后可用。
风险检测
风险识别器利用处理器指令行程表的信息计算风险。ScheduleHazardRecognizer class为风险识别器的实现提供了接口,ScoreboardHazardRecognizer subclass实现了记分牌风险识别器(见文件<llvm_source>/lib/CodeGen/ScoreboardHazardRecognizer.cpp),它是LLVM的默认识别器。
目标提供自己的识别器是允许的。这是必需的,因为TableGen可能无法表达具体的约束,这时必须提供定制的实现。例如,ARM和PowerPC都提供了ScoreboardHazardRecognizer subclass。
调度单元
调度器在寄存器分配之前和之后运行。然而,只有前者可使用SDNode指令表示,而后者使用MachineInstr class。为了兼顾SDNode和MachineInstr,SUnit class(见文件<llvm_source>/include/llvm/CodeGen/ScheduleDAG.h)抽象了背后的指令表示,作为指令调度期间的单元。llc工具可以用选项-view-sunit-dags输出调度单元。
机器指令
寄存器分配器工作在一种由MachineInstr class(简称MI)给出的指令表示之上,它的定义在<llvm_source>/include/llvm/CodeGen/MachineInstr.h。在指令调度之后,InstrEmitter Pass会被运行,它将SDNode格式转换为MachineInstr格式。如名字的含义,这种表示比IR指令更接近实际的目标指令。与SDNode格式及其DAG形式不同,MI格式是程序的三地址表示,即指令的序列而不是DAG,这让编译器能够高效地表达一个具体的调度决定,也就是决定每个指令的顺序。每个MI有一个操作码(opcode)数字和几个操作数,操作码只对一个具体的后端有意义。
利用llc选项-print-machineinstrs,可以输出所有注册的Pass之后的机器指令,或者利用选项-print-machineinstrs=<pass-name>输出一个特定的Pass之后的机器指令。我们从LLVM源代码中查找这些Pass的名字。为此,进入LLVM源代码文件夹,运行grep查找Pass注册它们的名字时常用到的宏:
$ grep -r INITIALIZE_PASS_BEGIN * CodeGen/
PHIElimination.cpp:INITIALIZE_PASS_BEGIN(PHIElimination, "phi-node-elimination"
(...)
例如,看下面sum.bc的每个Pass之后的SPARC机器指令:
$ llc -march=sparc -print-machineinstrs sum.bc
Function Live Ins: %I0 in %vreg0, %I1 in %vreg1
BB#0: derived from LLVM BB %entry Live Ins: %I0 %I1
%vreg1<def> = COPY %I1; IntRegs: %vreg1
%vreg0<def> = COPY %I0; IntRegs: %vreg0
%vreg2<def> = ADDrr %vreg1, %vreg0; IntRegs: %vreg2, %vreg1, %vreg0
%I0<def> = COPY %vreg2; IntRegs: %vreg2
RETL 8, %I0<imp-use>
MI包含关于指令的重要元信息:它存储被使用和被定义的寄存器,区别寄存器和内存操作数(以及其它类型),存储指令类型(分支、返回、调用、结束,等等),预测运算是否可交换,等等。保存这些信息甚至在像MI这样的低层次是重要的,因为在InstrEmitter之后代码输出之前运行的Pass要根据这些字段执行它们的分析。
寄存器分配
寄存器分配的基本任务是将无限数量的虚拟寄存器转换为有限的物理寄存器。由于目标的物理寄存器数量有限,有些虚拟寄存器被安排到内存位置,即spill slot。然而,有些MI代码可能已经用到了物理寄存器,甚至在寄存器分配之前。当机器指令需要将结果写到特定的寄存器,或者出于ABI的需求,这种情况就会发生。对此,寄存器分配器承认先前的分配行为,在此基础上将其余的物理寄存器分配给剩余的虚拟寄存器。
LLVM寄存器分配器的另一个重要任务是解构IR的SSA形式。直到此时,机器指令可能还包含phi指令,它们从原始的LLVM IR复制而来,为了支持SSA形式它们是必需的。如此,你可以方便地在SSA之上实现机器特定的优化。然而,传统的将phi指令转换为常规指令的方法,是用复制指令替换它们。这样,SSA解构不能晚于寄存器分配,这个阶段将会分配寄存器并且消除冗余的复制操作。
LLVM有四种寄存器分配方法,这可以在llc中选择,通过-regalloc=<regalloc_name>选项。可选的<regalloc_name>有:pbqp,greedy,basic,和fast。
pbqp:这种方法将寄存器分配映射为分区布尔二次规划(PBQP: Partitioned Boolean Quadratic Programming)问题。一个PBQP解决方法用于将这个问题的结果映射回寄存器。 greedy:这种方法给出一种高效的全局(函数范围)寄存器分配实现,支持活跃区域分割以最小化挤出(spill)。这里给出了关于这个算法的生动的解释:http://blog.llvm.org/2011/09/greedy-register-allocation-in-llvm-30.html。 basic:这种方法是一种很简单的分配器,并提供扩展接口。因此,它为开发新的寄存器分配器提供基础,被用作寄存器分配效率的基线。在前面的关于greedy算法的blog链接中,也有关于这个算法的内容。 fast:这种分配器是局部的(作用于各个基本块),它尽量地将值保持在寄存器中并重用它们。
default分配器被映射为这四种方法的其中之一,根据当前的优化级别(-O选项)作出选择。
虽然寄存器分配器在一个单一的Pass中实现,不管选择何种算法,但是它仍然依赖其它的分析,这构成了分配器框架。分配器框架用到一些Pass,这里我们介绍寄存器合并器和寄存器重写,解释它们的概念。下图阐明了这些Pass如何相互交互。
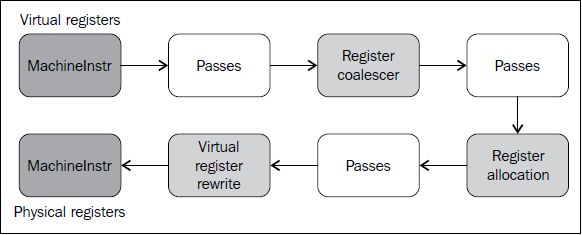
寄存器合并器
寄存器合并器(coalescer)通过结合值区间(interval)去除冗余的复制指令(COPY)。RegisterCoalescer class实现了这种合并(见lib/CodeGen/RegisterCoalescer.cpp),它是一个机器函数Pass。机器函数Pass类似于IR Pass,它运行在每个函数之上,只是处理的不是IR指令,而是MachineInstr指令。在合并期间,方法joinAllIntervals()复制指令的列表。方法joinCopy()从机器复制指令创建CoalescerPair实例,并且在可能的时候合并掉复制指令。
值区间(interval)表示程序中的一对点,开始和结束,它从一个值被产生时开始,直到这个值最终被使用,也就是说,被消灭(killed),期间它被保存在临时位置上。让我们看看合并器运行在我们的sum.bc bitcode例子上时会发生什么。
我们利用llc中的regalloc调试选项来查看合并器的调试输出:
$ llc -march=sparc -debug-only=regalloc sum.bc 2>&1 | head -n30
Computing live-in reg-units in ABI blocks.
0B BB#0 I0#0 I1#0
********* INTERVALS **********
I0 [0B,32r:0) [112r,128r:1) 0@0B-phi 1@112r
I1 [0B,16r:0) 0@0B-phi
%vreg0 [32r,48r:0) 0@32r
%vreg1 [16r,96r:0) 0@16r
%vreg2 [80r,96r:0) 0@80r
%vreg3 [96r,112r:0) 0@96r
RegMasks:
********** MACHINEINSTRS **********
# Machine code for function sum: Post SSA
Frame Objects:
fi#0: size=4, align=4, at location[SP]
fi#1: size=4, align=4, at location[SP]
Function Live Ins: $I0 in $vreg0, $I1 in %vreg1
0B BB#0: derived from LLVM BB %entry
Live Ins: %I0 %I1
16B %vreg1<def> = COPY %I1<kill>; IntRegs:%vreg1
32B %vreg0<def> = COPY %I0<kill>; IntRegs:%vreg0
48B STri <fi#0>, 0, %vreg0<kill>; mem:ST4[%a.addr]
IntRegs:%vreg0
64B STri <fi#1>, 0, %vreg1; mem:ST4[%b.addr] IntRegs:$vreg1
80B %vreg2<def> = LDri <fi#0>, 0; mem:LD4[%a.addr]
IntRegs:%vreg2
96B %vreg3<def> = ADDrr %vreg2<kill>, %vreg1<kill>;
IntRegs:%vreg3,%vreg2,%vreg1
112B %I0<def> = COPY %vreg3<kill>; IntRegs:%vreg3
128B RETL 8, %I0<imp-use,kill>
# End machine code for function sum.
备注
你可以用-debug-only选项对一个特定的LLVM pass或者组件开启内部调试消息。为了找出调试的组件,可在LLVM源代码文件夹中运行grep -r “DEBUG_TYPE” *。DEBUG_TYPE定义标记选项,它激活当前文件的调试消息,例如在寄存器分配的实现文件中有#define DEBUG_TYPE “regalloc”。
注意,我们用2>&1重定向了打印调试信息的标准错误输出到标准输出。然后,管道标准输出(包含调试信息)到head -n30,只打印前面的30行。以这种方式,我们控制了显示在终端上的信息量,因为调试信息可能相当繁琐。
首先让我们来看** MACHINEINSTRS **输出。这打印了作为寄存器合并器输入的所有机器指令——如果你用-print-machine-insts=phi-node-elimination选项输出(运行于合并器之前的)phi节点消除pass之后的机器指令,将得到相同的内容。然而,合并器调试器的输出,用索引信息给每条机器指令作提示:0B, 16B, 32B等。我们需要它们以正确地解释值区间(interval)。
这些索引也被称为slot indexes,给每个活跃区域(live range)赋予一个不同的数字。字母B对应基本块(block),被用于活跃区域进入或者离开一个基本块的边界。在此例中,我们的指令打印为索引跟着B,因为这是默认单元(slot)。在值区间中,有一个不同的单元,字母r,它表示寄存器,用于指示普通寄存器的使用或者定义。
通过阅读机器指令序列,我们已经知道了寄存器分配器超级Pass(若干小Pass的组合)的重要内容:%vreg0, %vreg1, %vreg2, %vreg3都是虚拟寄存器,需要为它们分配物理寄存器。因此,最多要使用4个物理寄存器,除了%I0和%I1之外,它们已经在使用了。其原因是为了遵守ABI调用惯例,它要求函数参数存于这些寄存器中。由于活跃变量分析Pass在寄存器合并之前运行,代码也标注了活跃变量信息,展示了每个寄存器在何处被定义和杀死,这让我们能够看清楚哪些寄存器相互冲突,即哪些寄存器同时活跃,需要保持在不同的物理寄存器中。
另一方面,合并器不依赖寄存器分配器的结果,它只是寻找寄存器复制。对于寄存器到寄存器的复制,合并器会尝试结合源寄存器和目标寄存器的值区间,让它们保持在相同的物理寄存器中,消除复制指令,就像索引16和32的复制。
紧跟着*** INTERVALS ***的消息,来自寄存器合并所依赖的另一个分析:活跃值区间分析(不同于活跃变量分析),它由 lib/CodeGen/LiveIntervalAnalysis.cpp实现。合并器需要知道每个虚拟寄存器所活跃的值区间,这样才能发现哪些值区间可以合并。例如,我们可以从输出中看到,虚拟寄存器%vreg0的值区间被确定为[32r:48r:0)。
这意味着这个半开放的值区间%vreg0在32处被定义,在48处被杀死。48r后面的数字0是一个代码,它显示这个值区间在何处被第一次定义,这个意思恰好在值区间后面被打印出来:o:32r。这样,定义o出现在索引32,这是我们已经知道的。然而,这可以让我们有效地追踪原始定义,监控值区间是否分裂。最后,RegMasks显示了调用现场,它清理了很多寄存器,是冲突的一个大源头。因为这个函数中没有任何调用,所以没有RegMasks位置。
通过观察值区间,我们有喜人的发现:%I0寄存器的值区间是[0B, 32r:0),%vreg0寄存器的值区间是[32r, 48r:0),在32处,有一条复制指令,它复制%I0到%vreg0。这就是合并发生的前提:结合值区间[0B, 32r:0)和[32r, 48r:0),赋给%I0和%vreg0相同的寄存器。
下面,让我们打印其余的调试输出,看看发生了什么:
$ llc -match=sparc -debug-only=regalloc sum.bc
...
entry:
16B %vreg1<def> = COPY %I1;
IntRegs: %vreg1
Considering merging %vreg1 with %I1
Can only merge into reserved registers.
32B %vreg0<def> = COPY %I0;
IntRegs:%vreg0
Considering merging %vreg0 with %I0
Can only merge into reserved registers.
64B %I0<def> = COPY %vreg2;
IntRegs:%vreg2
Considering merging %vreg2 with %I0
Can only merge into reserved registers.
...
我们看到,合并器考虑结合%vreg0和%I0,如我们希望的那样。然而,当寄存器是物理寄存器时,例如%I0,它实行了特殊的规则。物理寄存器必须保留以连接它的值区间。这意味着,不能将物理寄存器分配给其它的活跃区域,而%I0的情况并非如此。因此,合并器放弃了这个机会,它担心过早地把%I0分配给这整个区间到最后可能无法获益,留由寄存器分配器作这个决定。
因此,程序sum.bc没有合并的机会。虽然它试图结合虚拟寄存器和函数参数寄存器,但是失败了,因为在此阶段它只能将虚拟寄存器和保留的——非常规可分配的——物理寄存器相结合。
虚拟寄存器重写
寄存器分配Pass为每个虚拟寄存器选择物理寄存器。随后,VirtRegMap保存了寄存器分配的结果,它将虚拟寄存器映射到物理寄存器。接着,虚拟寄存器重写Pass——由VirtRegRewriter class表示,它的实现在文件<llvm_source>/lib/CodeGen/VirtRegMap.cpp 中——利用VirtRegMap将虚拟寄存器替换为物理寄存器。根据情况会生成spill代码。而且,剩下的恒等复制reg = COPY reg会被删除。例如,让我们利用-debug-only=regalloc选项分析分配器和重写器如何处理sum.bc。首先,greedy分配器输出如下文本:
...
assigning %vreg1 to %I1: I1
...
assigning %vreg0 to %I0: I0
...
assigning %vreg2 to %I0: I0
虚拟寄存器1, 0, 2分别被分配以物理寄存器%I1, %I0, %I0。VirtRegMap输出中给出了相同的内容,如下:
[%vreg0 -> %I0] IntRegs
[%vreg1 -> %I1] IntRegs
[%vreg2 -> %I0] IntRegs
然后,重写器将所有虚拟寄存器替换为物理寄存器,并删除恒等的复制:
> %I1<def> = COPY %I1
Deleting identity copy.
> %I0<def> = COPY %I0
Deleting identity copy.
...
我们看到,尽管合并器无法去除这些复制,但是寄存器分配器能够为两个活跃区域赋以相同的寄存器,并删除复制操作,如我们希望的那样。最终,作为结果的sum函数的机器指令极大地简化了:
0B BB#0: derived from LLVM BB
%entry
Live Ins: %I0 %I1
48B %I0<def> = ADDrr %I1<kill>, %I0<kill>
80B RETL 8, %I0<imp-use>
注意,复制指令被删除了,没有剩下虚拟寄存器。
备注
只有当LLVM以debug模式编译(通过在配置时刻设置–disable-optimized)后,才能使用llc程序的选项-debug或者-debug-only=<name>。你可以在第1章(编译和安装LLVM)的**Building and installing LLVM**小节找到更多相关内容。
在任何编译器中,寄存器分配和指令调度都是天生的敌人。寄存器分配的任务是尽可能让活跃区域短一点,减少冲突图的边的数目,而减少所需寄存器的数目,以避免挤出(spill)。因而,寄存器分配器喜欢以串行的模式排列指令(让指令紧跟在其所依赖指令的后面),因为用这种方法代码所用的寄存器相对较少。指令调度的任务是相反的:为了提升指令级别的并行,需要尽可能地让很多无关而并行的运算保持活跃,要用很多寄存器保存中间值,增加活跃区域之间冲突的数量。设计一个有效的算法来协同地处理指令调度和寄存器分配,是一个开放的研究课题。
目标钩子
在合并的时候,虚拟寄存器来自相容的寄存器类别,需要被顺利地合并。代码生成器从目标特定的描述获得这类信息,而描述由抽象方法给出。分配器可以从TargetRegisterInfo的子类(例如X86GenRegisterInfo)获得所有关于一个寄存器的信息。这些信息包括,是否为保留的,父寄存器类别,是物理的还是虚拟的寄存器。
<Target>InstrInfo类是另一个提供寄存器分配器所需要的目标特定的信息的数据结构。这里讨论一些例子:
<Target>InstrInfo的isLoadFromStackSlot()和isStoreToStackSlot()方法,用于在挤出代码生成期间发现机器指令访问栈单元的内存。
此外,它用storeRegToStackSlot()和loadRegFromStackSlot()方法生成访问栈单元的目标特定的内存访问指令。
COPY指令可能在寄存器重写之后保留下来,因为它们没有被合并掉,而且不是同一的复制。在这种情况下,copyPhysReg()方法用于生成目标特定的寄存器复制,在需要时甚至在不同寄存器类别之间。SparcInstrInfo::copyPhysReg()的例子是这样的:
if (SP::IntRegsRegClass.contains(DestReg, SrcReg))
BuildMI(MBB, I, DL, get(SP::ORrr), DestReg).addReg(SP::G0)
.addReg(SrcReg, getKillRegState(KillSrc));
...
BuildMI()方法在代码生成器中到处可见,它用于生成机器指令。在这个例子中,SP::ORrr指令用于复制一个CPU寄存器到另一个CPU寄存器。
序曲和尾声
完整的函数都需要序曲(prologue)和尾声(epilogue)。前者在函数的开始处设置堆栈帧和被调用者保存的寄存器,而后者在函数返回前清理堆栈帧。在例子sum.bc中,当为SPARC编译时,插入序曲和尾声之后,机器指令看起来是这样的:
%06<def> = SAVEri %06, -96
%I0<def> = ADDrr %I1<kill>, %I0<kill>
%G0<def> = RESTORErr %G0, %G0
RETL 8, %I0<imp-use>
此例中,SAVEri指令是序曲,RESTORErr是尾声,执行堆栈帧相关的设置和清理。序曲和尾声的生成是目标特定的,由方法<Target>FrameLowering::emitPrologue()和<Target>FrameLowering::emitEpilogue()定义(参见文件<llvm_source>/lib/Target/<Target>/<Target>FrameLowering.cpp)。
帧索引
LLVM在代码生成期间用到一个虚拟堆栈帧,利用帧索引引用堆栈元素。序曲的插入会分配堆栈帧,给出充足的目标特定的信息,让代码生成器得以将虚拟帧索引替换为实际的(目标特定)堆栈引用。
<Target>RegisterInfo类的eliminateFrameIndex()方法实现了所述替换,就是检查所有包含堆栈引用(通常为load和store)的机器指令,将每个帧索引转换为实际的堆栈偏移。当需要额外的堆栈偏移算术运算时,也会生成额外的指令。参见文件<llvm_source>/lib/Target/<Target>/<Target>RegisterInfo.cpp作为例子。
理解机器代码框架
机器代码(简称MC)类包含整个低层操作函数和指令的框架。对比其它的后端组件,这是一个新设计的框架,助于创建基于LLVM的汇编器和反汇编器。之前,LLVM缺少一个集成的汇编器,编译过程只能进行到汇编语言生成这一步,它创建一个汇编文本文件,要依靠外部的工具继续剩余的编译工作(汇编器和链接器)。
MC指令
在MC框架中,机器代码指令(MCInst)替代了机器指令(MachineInstr)。在文件<llvm_source>/include/llvm/MC/MCInst.h中定义的MCInst类,定义了对指令的轻量表示。对比MI(机器指令),MCInst记录较少的程序信息。例如,MCInst实例不仅可以由后端创建,而且可以由反汇编器只根据二进制代码创建,注意反汇编器是一个缺少指令上下文信息的环境。事实上,它融入了汇编器的理念,也就是说,其目的不是应用丰富的优化,而是组织指令生成目标文件。
每个操作数可以是一个寄存器,立即数(整数或浮点数),表达式(表示为MCExpr),或者另一个MCInstr实例。表达式用于表示标记(label)运算和重定位。MI指令在代码生成阶段的早期被转换为MCInst实例,这是下个小节的主题。
代码输出
代码输出阶段处于所有后寄存器分配Pass之后。尽管名字似乎让人难于理解,代码生成从汇编打印(AsmPrinter)开始。下面的示意图给出了从MI指令到MCInst接着到汇编或者二进制指令的步骤:
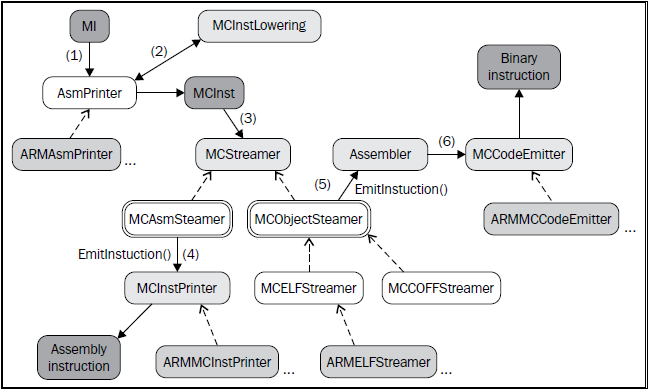
让我们逐一介绍上图所示的步骤:
AsmPrinter是一个机器函数Pass,它首先生成函数头,然后遍历所有基本块,每次发送一个MI指令到方法EmitInstruction(),以作进一步处理。每个目标会提供一个AsmPrinter子类,它重载这个方法。
<Target>AsmPrinter::EmitInstruction()方法接收MI指令作为输入,凭借MCInstLowering接口将它转变为MCInst实例——每个目标会提供这个接口的子类,自定义生成这些MCInst实例的程序。
此刻,可以接着生成汇编或者二进制指令。MCStreamer类处理MCInst指令流,通过两个子类,MCAsmStreamer和MCObjectStreamer,将指令输出为所选的格式。前者将MCInst转换为汇编语言,而后者将它转换为二进制指令。
如果生成汇编指令,就会调用MCAsmStreamer::EmitInstruction(),由一个目标特定的MCInstPrinter子类打印汇编指令到文件。
如果生成二进制指令,MCObjectStreamer::EmitInstruction()的一个目标(target)专用的、目标代码(object)特定的版本就会调用LLVM目标代码汇编器。
汇编器会利用一个专用的MCCodeEmitter::EncodeInstruction()方法,蜕变MCInst实例,编码和输出二进制指令数据块到文件,以一种目标特定的方式。
此外,你可以用llc工具输出MCInst片段。例如,要将MCInst编码为汇编注释,可以用下面的命令:
$ llc sum.bc -march=x86-64 -show-mc-inst -o -
...
pushq %rbp ## <MCInst #2114 PUSH64r
## <MCOperand Reg: 107>>
…
然而,如果你想要将每条指令的二进制编码显示为汇编注释,就用下面的命令:
$ llc sum.bc -march=x86-64 -show-mc-encoding -o -
...
push %rbp ## encoding: [0x55]
...
llvm-mc工具还让你能够测试和使用MC框架。例如,为了查明一条特定指令的汇编编码,使用选项–show-encoding。下面是x86指令的一个例子:
$ echo "movq 48879(,%riz), %rax" | llvm-mc -triple=x86_64 --show-encoding
#encoding:
[0x48, 0x8b, 0x04, 0x25, 0xef, 0xbe, 0x00, 0x00]
这个工具还提供了反汇编的功能,如下:
$ echo "0x8d 0x4c 0x24 0x04" | llvm-mc --disassemble -triple=x86_64
leal 4(%rsp), %ecx
另外,选项–show-inst为经过汇编或反汇编的指令显示MCInst指令:
$ echo "0x8d 0x4c 0x24 0x04" | llvm-mc --disassemble --show-inst -triple=x86_64
leal 4(%rsp), %ecx # <MCInst #1105 LEA64_32r
# <MCOperand Reg:46>
# <MCOperand Reg:115>
# <MCOperand Imm:1>
# <MCOperand Reg:0>
# <MCOperand Imm:4>
# <MCOperand Reg:0>>
MC框架让LLVM能够为经典的目标文件阅读器提供可选择的工具。例如,目前默认编译LLVM会安装llvm-objdump和llvm-readobj工具。两者都用到了MC反汇编库,实现了跟GNU Binutils软件包中的等价物(objdump和readelf)相类似的功能。
编写你自己的机器Pass
在这个章节,我们将示范如何编写一个定制的机器Pass,它正好在代码生成之前,统计每个函数有多少机器指令。不同于IR Pass,你不能用opt工具运行这个Pass,或通过命令行加载并安排它运行。机器Pass由后端代码管理。因此,在实践中我们修改一个已有的后端来运行并观察我们定制的Pass。我们选择SPARC后端。
回想第3章(工具和设计)的演示插件式Pass接口小节,从这章的第一张图的白框中,有很多选项供我们选择决定在何处运行我们的Pass。为了应用这些方法,我们应该找到我们的后端实现的TargetPassConfig子类。如果你用grep,就会在SparcTargetMachine.cpp中找到它:
$ cd <llvmsource>/lib/Target/Sparc
$ vim SparcTargetMachine.cpp # 使用你喜欢的编辑器
观察这个从TargetPassConfig派生的SparcPassConfig类,我们看到它覆写(override)了addInstSelector()和addPreEmitPass(),但是我们可以覆写很多方法,如果我们想要在其它的地方添加一个Pass(见链接http://llvm.org/doxygen/html/classllvm_1_1TargetPassConfig.html)。我们将在代码生成前运行我们的Pass,因此在addPreEmitPass()中添加代码:
bool SparcPassConfig::addPreEmitPass() {
addPass(createSparcDelaySlotFillerPass(
getSparcTargetMachine()));
addPass(createMyCustomMachinePass());
}
在上面的代码中,高亮的行是我们额外添加的,它通过调用函数createMyCustomMachinePass()来添加我们的Pass。然而,这个函数还未定义。我们将增加一个新的源代码文件,编写Pass代码,也会定义这个函数。于是,创建一个文件,名为MachineCountPass.cpp,填写下面的内容:
#define DEBUG_TYPE "machinecount"
#include "Sparc.h"
#include "llvm/Pass.h"
#include "llvm/CodeGen/MachineBasicBlock.h"
#include "llvm/CodeGen/MachineFunction.h"
#include "llvm/CodeGen/MachineFunctionPass.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace {
class MachineCountPass : public MachineFunctionPass {
public:
static char ID;
MachineCountPass() : MachineFunctionPass(ID) {}
virtual bool runOnMachineFunction(MachineFunction &MF) {
unsigned num_instr = 0;
for (MachineFunction::const_iterator I = MF.begin(), E = MF.end(); I != E; ++I) {
for (MachineBasicBlock::const_iterator BBI = I->begin(), BBE = I->end(); BBI != BBE; ++BBI) {
++num_instr;
}
}
errs() << "mcount --- " << MF.getName() << " has " << num_instr << " instructions.\n";
return false;
}
};
}
FunctionPass *llvm::createMyCustomMachinePass() {
return new MachineCountPass();
}
char MachineCountPass::ID = 0;
static RegisterPass<MachineCountPass> X("machinecount", "Machine Count Pass");
在第一行中,我们定义了宏DEBUG_TYPE,这样以后我们就可以通过选项-debug-only=machinecount调试这个Pass。然而,在这个例子中,没有用到调试输出。剩余的代码和我们前一章为IR Pass写的很相似。不同之处如下:
在包含文件中,我们包含了头文件MachineBasicBlock.h, MachineFunction.h, MachineFunctionPass.h,它们定义了我们用于提取MachineFunction信息的类,让我们能够计数它包含的机器指令。我们还包含了头文件Sparc.h,因为我们将声明createMyCustomMachinePass()。
我们创建了一个类,从MachineFunctionPass派生,而不是从FunctionPass。
我们覆写了runOnMachineFunction()方法,而不是runOnFunction()。另外,方法的实现是相当不同的。我们遍历了当前MachineFunction中的所有MachineBasicBlock实例。然后,对于每个MachineBasicBlock,调用begin()/end()语句以计数所有的机器指令。
我们定义了函数createMyCustomMachinePass(),让这个Pass在我们所修改的SPARC后端文件中被创建和添加为代码生成之前的Pass。
既然已经定义了函数createMyCustomMachinePass(),我们就必须在头文件中声明它。让我们编辑Sparc.h文件来做这件事。在createSparcDelaySlotFillerPass()的后面添加我们的函数声明:
FunctionPass *createSparcISelDag(SparcTargetMachine &TM);
FunctionPass *createSparcDelaySlotFillerPass(TargetMachine &TM);
FunctionPass *createMyCustomMachinePass();
下面让我们用LLVM编译系统编译新的SPARC后端。如果你还没有配置你的LLVM编译系统,就参考第1章(编译和安装LLVM)。如果你已经有了配置项目的build文件夹,就进入这个文件夹,运行make以编译新的后端。接着,你可以安装包含修改了的SPARC后端的新的LLVM,或者依你所愿,只是从你的build文件夹运行新的llc二进制程序,而不运行make install:
$ cd <llvm-build>
$ make
$ Debug+Asserts/bin/llc -march=sparc sum.bc
mcount --- sum has 8 instructions.
如果我们想知道我们的Pass在Pass管线中被插入在什么位置,输入下面的命令:
$ Debug+Asserts/lib/llc -march=sparc sum.bc -debug-pass=Structure
(...)
Branch Probability Basic Block Placement
SPARC Delay Slot Filler
Machine Count Pass
MachineDominator Tree Construction
Sparc Assembly Printer
mcount --- sum has 8 instructions.
我们看到,我们的Pass恰好被安排在SPARC Delay Slot Filler之后,在Sparc Assembly Printer之前,后者是代码生成发生的地方。
总结
在这一章中,我们概要地介绍了LLVM后端是如何工作的。我们看到了不同的代码生成阶段,以及在编译过程中变化的内部指令表示。我们讨论了指令选择、调度、寄存器分配、代码生成,为读者演示了用LLVM工具对这些阶段做实验的方法。在本章结束的时候,你应该能够读懂llc -debug的输出,它打印出后端活动的详细的日志,展示了发生在后端内部的一切事情的全貌。如果你有兴趣编写自己的后端,你的下一步就是参考官方的教程:http://llvm.org/docs/WritingAnLLVMBackend.html。如果你有兴趣阅读更多的关于后端设计的内容,你应该参考http://llvm.org/docs/CodeGenerator.html。
在下一章中,我们将介绍LLVM Just-in-Time编译框架,它让你能够按需要随时地生成代码。